
Perda de Dados e Ações Pós Incidente
Criado em 19/11/2019. Atualizado em 27/10/2023.
Introdução
Após duas décadas observando a reação de empresas diante de desastres com perda de dados, ficou evidente a adoção de alguns padrões e procedimentos comuns a todas elas. Tanto em desastres causados por danos em hardware, quanto em incidentes ocorridos em nível lógico, as respostas poderiam ser aprimoradas para evitar maiores prejuízos e proporcionar uma recuperação satisfatória.
Erros Comuns

Incidentes com perda de acesso a dados críticos, maioria dos casos, deveriam exigir respostas rápidas e precisas. No entanto, há uma certa morosidade inerente às políticas usualmente adotadas, assim como o uso de práticas que apresentam riscos para os ambientes a serem recuperados.
Em empresas de pequeno e médio porte, danos em storage e perda de dados são frequentemente indentificados pelos usuários que acessam os recursos comprometidos (quando deveriam ter sido detectados por um administrador ou analista). É comum haver lentidão entre chamados e reuniões, até que alguma resposta efetiva seja realizada. Por outro lado, instituições de grande porte têm equipes responsáveis pela monitoração de storages e recursos de armazenamento. Na maioria dos casos, as equipes de backup e disaster recovery fazem com que a reação seja imediata e eficiente.
No entanto, procedimentos invasivos de verificação e tentativas contraindicadas de restabelecimento dos recursos podem ocorrer em empresas de todos os portes. Um exemplo de ação não recomendada é o rebuilding em RAID com drives (HDs, SSDs, etc.) corrompidos, que é usual a muitos analistas desavisados. Tal ação pode quebrar a consistência de metadados e comprometer os dados alocados. Portanto, há certos riscos quando se configura controladoras ou sistemas para fazerem auto-rebuilding.
Outro procedimento indevido é o escaneamento de setores ou blocos em discos físicos com mal funcionamento. Infelizmente, ferramentas como chkdsk, sfc (/scannow), fsck, entre outras, costumam ser usadas de forma equivocada por analistas que acreditam poder "reparar" discos danificados com elas. Estes programas não foram (ou não deveriam ser) desenvolvidos para tal propósito e são um gatilho para dispositivos de armazenamento em estado de pré-falha; além de agravar os danos em drives que já estejam defeituosos. Não existem softwares que consertam problemas físicos em dispositivos de armazenamento.
Nas empresas de porte menor é comum que tarefas as quais deveriam ser realizadas por uma equipe de disaster recovery, sejam executadas por um analista interno sem treinamento nesse segmento.
Mitigação
Em ambientes com poucos recursos é comum haver certa ineficiência e morosidade em detectar e responder às falhas de storage. O mesmo ocorre em perdas de dados causada por acidentes (exclusão de arquivos, tabelas de partição, etc.) e ações dolosas (espionagem industrial, vandalismo digital, etc.).
Mesmo nas instituições de maior porte, procedimentos que apresentam riscos para drives avariados são realizados com certa frequência, podendo agravar o prejuízo causado pelo incidente e dificultar a recuperação do conteúdo. Não, necessariamente, são ações absurdas (como violação de discos ou uso de programinhas "milagrosos" que prometem regenerar um HD). Frequentemente, são procedimentos aparentemente inofensivos, mas com potencial de destruir discos em estado precário ou causar inconsistência permanente em volumes e/ou sistemas de arquivos.
Dispositivos de armazenamento (HD, SSD, flash drive, etc.) danificados precisam ser preservados e tratados como objetos de perícia. Em ambientes com informações críticas, eles devem ser desligados assim que constatado qualquer sinal de mal funcionamento, principalmente nos desastres que impedem o acesso aos dados alocados.
Um ambiente computacional que sofre perda de dados críticos deve ter seus drives desativados ou bloqueados para leitura e escrita. Estas ações mitigam o incidente e aumentam a chance de reparo dos drives, das estruturas lógicas e, consequentemente, do conteúdo.
Controladoras de storage realocam setores (em nível de firmware de drive) de forma direta ou blocos (em nível de volume ou sistema de arquivos) de forma indireta, quando encontram áreas danificadas nas mídias de armazenamento. Qualquer operação de leitura ou gravação em drive avariado é suficiente para disparar essas rotinas. Isso pode tormar proporções gigantescas durante escaneamentos de setores ou blocos, através de programas como HDtune ou utilitários como chkdsk e fsck. Um problema grave causado por essas ações invasivas é a perda dos dados contidos nos setores que foram realocados. Outro problema sério é o agravamento do dano físico em HDs, degradando cabeças de leitura, pratos magnéticos e causando inconsistências em módulos de firmware. Portanto, esses procedimentos podem ocasionar perda irreversível de dados, inviabilizando, até mesmo, uma ação profissional de recuperação de dados.
Melhores Práticas
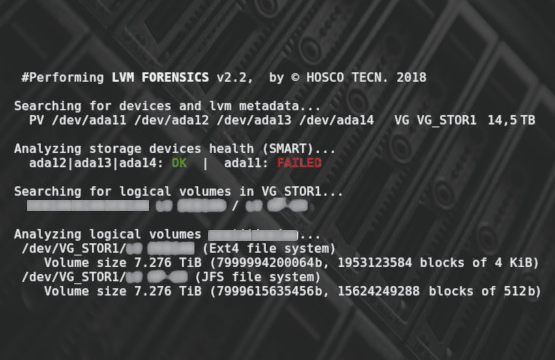
O SMART é um excelente aliado dos usuários, técnicos e analistas. Essa tecnologia caracteriza-se por um conjunto de rotinas contidas no sistema do próprio drive de armazenamento, que reporta o seu estado de funcionamento. Programas como o Gsmartcontrol conseguem interpretar os logs do SMART, mostrando detalhes sobre o status do dispositivo.
A verificação do estado de saúde de uma mídia de storage (HD, SSD, flash drive, etc.) através da leitura do SMART é uma prática bastante recomendada por não ser invasiva. Além disso, é uma ação simples que pode ser realizada por um analista nivel 1, diminuindo os tempos de resposta aos desastres causados por mau funcionamento desses equipamentos.
Em ambientes Linux e Unix, a libata é um bom marcador (não invasivo) na detecção de problemas em discos. É uma biblioteca no kernel, responsável por gestão de eventuais erros nos drives usados pelo sistema operacional. Basta verificar se a saída do comando dmesg apresenta mensagens (geradas pelo kernel) de erros de leitura ou escrita. Trata-se de uma análise passiva segura e totalmente confiável.
Os sistemas de arquivos também emitem sinais claros quando existem devices de storage com mal funcionamento. Em plataformas Windows, é comum o gerenciador de tarefas indicar uso de disco em 100%. Em plataformas Unix, serão observados picos de processamento com threads de I/O (kworker, jdb2, etc.).
Em empresas maiores é incomum a verificação das formas citadas acima. São usadas soluções de monitoramento presentes em servidores e storages de grandes vendors, como Oracle HMP, IBM TSM, Dell OpenManage, Supermicro SuperDoctor, etc. Estas ferramentas entregam as informações de modo que o administrador não precisa se preocupar em entender parâmetros de SMART ou analisar logs da libata.
Os incidentes relacionados à perda de dados por dano lógico costumam apresentar sinais mais claros; salvo certos casos furtivos de violação de sistemas.
Conclusão
O tempo de reação e a qualidade da resposta são muito importantes na recuperação de um ambiente com conteúdo indisponível. Burocracia, políticas arcaicas, ausência de planos de recuperação de desastre e ações invasivas, são os maiores agravadores de desastres com perda de dados.
Diante de tais circunstâncias deve-se adotar ações rápidas, eficientes e não invasivas. O mais importante é desativar, rapidamente, os dispositivos de armazenamento envolvidos, para evitar realocação de setores e corrompimento de metadados. Em ambientes com informações críticas, recomenda-se consultar uma empresa especializada em recuperação de dados.
É importante lembrar que a melhor prevenção contra perda de dados continua sendo a implementação de sistemas eficientes de backup. A substituição periódica e programda das mídias de armazenamento também deve fazer parte da gestão de infraestrutura e das tarefas preventivas de qualquer empresa.