
RAID
Criado em 03/08/2023 e revisado em 01/02/2026
Introdução
RAID (Redundant Array of Independent Disks) é uma tecnologia de armazenamento que combina múltiplos discos (HDs ou SSDs) em uma única unidade lógica para oferecer segurança contra perda de dados (redundância), maior velocidade (performance) e aumento de volume (capacidade). Em português, o termo significa Arranjo Redundante de Discos Independentes.
| Discos Quant. de Discos | Redund. Redundância | Perf. R/W Perf. (Leitura/Escrita) | Cap. Útil Capacidade Útil | |
|---|---|---|---|---|
| RAID-0 | Mín. 2 | Não há | Alta / Alta | 100% |
| RAID-1 | Mín. 2 | 1 disco | Média/Média Média / Média | 50% |
| RAID-5 | Mín. 3 | 1 disco | Média/Média Média / Média | 67-94% |
| RAID-6 | Mín. 4 | 2 discos | Média / Baixa | 50-88% |
| RAID-10 | Mín. 4 | 1 drv/grp 1 disco/grp | Alta / Média | 50% |
| RAID-50 | Mín. 6 | 1 drv/grp 1 disco/grp | Alta / Média | 67-94% |
| RAID-60 | Mín. 8 | 2 drv/grp 2 disco/grp | Alta / Média | 50-88% |
A implementação de RAID é indicada principalmente quando há necessidade de manter um serviço funcionando, mesmo com falha de disco, ou para aumentar desempenho de I/O. É essencial para servidores e unidades de storage em cenários de missão crítica.
Um disk array não pode ser considerado solução de backup porque mesmo reduzindo downtime por falha de disco, ele não protege contra exclusão acidental, corrupção lógica, erros humanos ou ataques de ransomware.
Embora a tecnologia também entregue aumento de disponibilidade, falhas críticas podem ocorrer. Em cenários de perda de acesso aos dados, incidentes com múltiplas falhas de disco ou corrupção lógica, é recomendado recorrer imediatamente a um serviço especializado em recuperar RAID, evitando tentativas manuais ou ações que podem comprometer o array permanentemente.
A maioria dos ambientes computacionais modernos usam algum tipo de RAID, com objetivo de aumentar o espaço para guardar arquivos, melhorar performance de armazenamento e garantir disponibilidade de serviços. Esta tecnologia, para armazenagem de dados, foi idealizada no começo dos anos 80, em resposta às demandas decorrentes da informatização em larga escala que começava a surgir ao final dos anos 70.
Este documento abrange os aspectos principais sobre a tecnologia RAID, como sua origem, conceito, características, indicações de uso e outros tópicos relevantes.

Níveis de RAID
Níveis Padronizados
Inicialmente, em 1988, a equipe de Berkley apresentou os níveis 0, 1, 2, 3, 4 e 5, e, posteriormente, idealizou o nível 6. Estes são os sete níveis padrão de RAID.
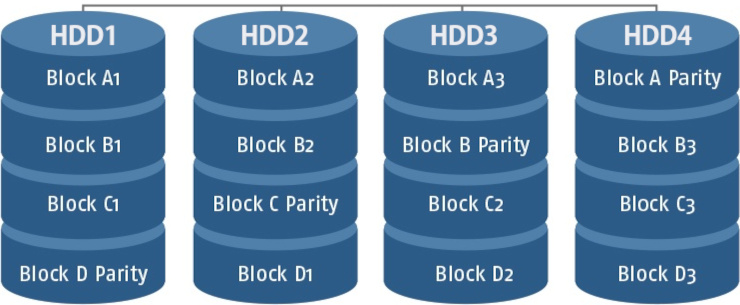
Níveis Híbridos
Os níveis híbridos ou aninhados (nested levels) foram criados pela indústria armazenamento de dados e consiste na combinação de diferentes níveis básicos (0 à 6) de RAID.
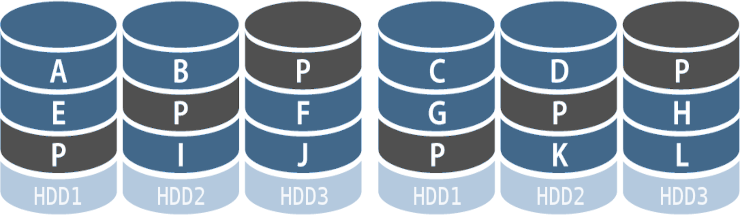
Conceito
Definição
Tecnicamente, o RAID consiste em uma tecnologia que mapeia dispositivos de armazenamento para um ou mais discos virtuais, atuando como uma camada de virtualização entre o sistema operacional e os dispositivos físicos. Ele distribui (striping) ou replica (mirroring) dados através de múltiplos drives, apresentando-os ao sistema como um único volume coerente. Isso permite superar as limitações físicas de um único disco em termos de IOPS, throughput e confiabilidade.
Atributos
- Redundância e maior segurança
- Maior poder de armazenamento
- Resiliência e disponibilidade
- Aumento em IOPS e performance
- Escalabilidade com facilidade
Indicação
- Backup com informações críticas
- Sistema de alto volume de dados
- Serviço de uptime maior que 99%
- Cenário que carece de alto IOPS
- Ambiente em expansão constante
Camada RAID
Na pilha de armazenamento, o RAID é uma camada de abstração que reúne dispositivos de bloco e expõe ao sistema um ou mais discos virtuais. Em geral, essa camada fica acima dos setores ou blocos dos discos e abaixo dos volumes lógicos de LVM (PV/VG/LV) e dos sistemas de arquivos.
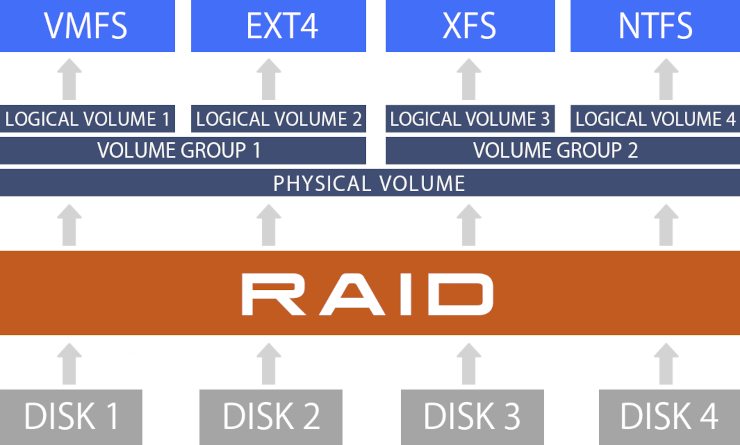
Termos Comuns
Definições rápidas dos termos usados neste guia.
- Array
-
Significa arranjo, conjunto ou matriz. Pode ser usado como sinônimo para RAID (conjunto de discos).
- Strip
-
Strip (listra) configura um conjunto de blocos localizados em um mesmo dispositivo físico (HD, SSD etc.).
- Stripe
-
Stripe (faixa) é um segmento de strips distribuídas entre os discos do array, com tamanho de 256KB à 512KB.
- Extent
-
Significa extensão. É uma região contígua em um disco físico.
- Virtual Disk
-
VD é um objeto apresentado como storage device ao host. Ao menos um dispositivo físico é associado ao VD.
- Physical Disk
-
PD, ou Physical Disk, significa "disco físico" e se refere a um dispositivo de armazenamento (HD, SSD, etc.).
- Basic Virtual Disk
-
BVD é um VD vinculado a níveis não híbridos de RAID, como RAID-0 ou 5. BDVs são compostos de discos físicos.
- Disk Group
-
DG é um agrupamento de discos físicos. Vários discos físicos podem ser combinados em um grupo de discos.
- Foreign configuration
-
Significa configuração externa. É uma configuração de RAID proveniente de uma outra controladora ou sistema.
- Pass-through Disk
-
Dispositivos físicos ligados a controladoras RAID, mas que são apresentados diretamente (como discos) ao host.
- Spare Disk
-
Disco de reserva, presente em RAID, que substitui, automaticamente, um disco ativo que para de funcionar.

Paridade
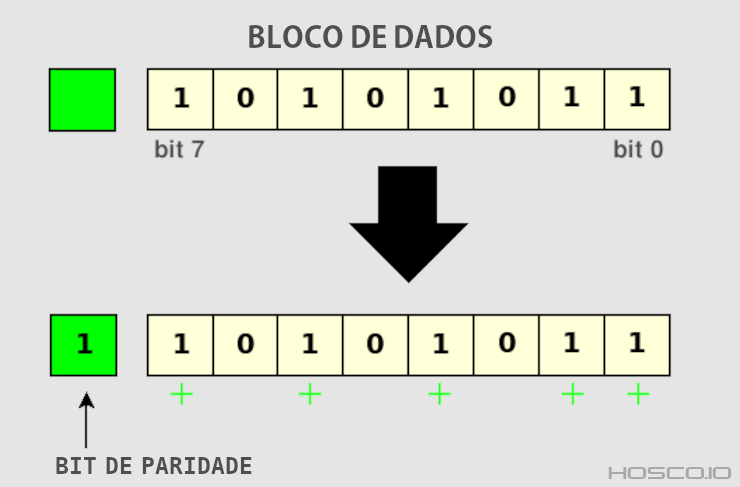
Definição
A paridade é o processo de introduzir um bit de controle (bit de paridade) em uma transmissão de dados, para detectar e resolver eventuais erros. A principal vantagem do uso de paridade como forma de controle de erros é que ela emprega um cálculo bem simples, consumindo poucos recursos de processamento. O bit de paridade pode ser ímpar ou par.
Exemplo: ao anexar um bit de paridade a um byte (8 bits) que está sendo transmitido, um erro pode ser detectado se a paridade do byte não coincidir com o bit de paridade.
Importância
Os RAID de nível 5 e 6, assim como seus derivados, usam usam sistema de paridade para correção de erros. Nestas tecnologias, blocos de dados possuem seus respectivos bits de paridade replicados em cada dispositivo do array. Na prática, se um bloco apresentar erro ou se um disco falhar, os dados perdidos podem ser recalculados e recuperados à partir de uma equação envolvendo as informações de paridade.
Estados do RAID
Um RAID, bem como seus discos físicos (PD) e seus discos virtuais (VD), podem ter diferentes estados de funcionamento. Estas condições operacionais são sinalizadas por bits específicos em áreas dedicadas nos physical disks (HDs, SSDs, etc.) e virtuals disks (abstrações do arranjo ou discos virtuais gerados à partir dele).
Disco Físico
Online
Disco ligado, teoricamente, saudável e apto para operar. No entanto, este estado não indica que o disco esteja lendo ou gravando dados.
Offline
Dispositivo desligado, desativado ou removido do RAID, seja em decorrência de uma falha de hardware ou por remoção manual e programada.
Failed
O estado failed indica que o disco deixou de ser reconhecido pela controladora e foi desativado por erros ou problemas de funcionamento.
Rebuilding
Ocorre em RAID com redundância e constitui a reconstrução ou sincronização de dados para um novo disco que substitui um disco defeituoso.
Not Rebuilding
Estado inerente à arrays com redundância, indicando que não há rebuilding (sincronização dos dados) e não há necessidade de que ocorra.
Transition
Estado temporário do RAID decorrente de uma alteração de configuração ou cópia de dados durante a reposição de um dispositivo danificado.
Not in Transition
Em oposição ao transition, este estado indica que um arranjo permanece estável e que não há processos de reconstrução ou sincronização.
PFA
PFA indica que um disco está na iminência de falhar e baseia-se no recurso Predictive Failure Analysis, presente em alguns sistemas RAID.
No PFA
É um estado antagônico ao PFA, presente em alguns sistemas e controladoras RAID, indicando que não há perigo iminente de falha em um drive.
Unrecovered Read Errors
Indica erros de leitura que não puderam ser reparados ou corrigidos, oriundos de drives com problemas nas cabeças de leitura, entre outros.
No Unrecovered Read Errors
Condição de funcionamento oposta ao Unrecovered Read Errors, sinalizando que não houveram erros de leitura, irreparáveis, até o momento.
Missing
Estado que um dispositivo de armazenamento para de enviar sinais à controladora ou sistema RAID, por erro de conexão ou falha de hardware.
Not Missing
Estado de funcionamento antagônico ao missing, mostrando que não há problema de comunicação entre drives e controladora ou sistema RAID.
Disco Virtual
Optimal
Modo operacional em que o arranjo ou disco virtual está funcionando, normalmente, sem quaisquer problemas em algum de seus discos físicos.
Partially Optimal
Arranjo que teve um ou mais problemas com drives e que poderá sofrer pelo menos mais uma falha de drive antes de entrar em estado degradado.
Degraded
O estado degraded sinaliza que o RAID está operando em modo "degradado" por causa de falha em um ou mais dispositivos do disco virtual.
Deleted
Um VD ou array marcado como deleted é um objeto que foi removido pelo sistema, de forma programada, através de uma ação de gerenciamento.
Missing
Um disco virtual é marcado como missing quando ele deixa de responder ao sistema, por causa de problemas de conexão ou erro de hardware.
Failed
Um RAID failed está inoperante em razão de terem havido falhas, em uma quantidade de discos físicos, que comprometeram a sua integridade.
Offline
O estado offline informa que o RAID ou disco virtual não está disponível para o sistema, normalmente, em virtude de manutenção ou reparo.
Morphing
Sinaliza que VD está sofrendo uma modificação: migração de nível, expansão de capacidade, mudança no tamanho do stripe ou desfragmentação.
Not Morphing
É o modo operacional oposto ao Morphing, o qual informa que o array não está sofrendo nenhum processo de modificação brusca de estrutura.
VD Consistent
Estado em que todas as gravações (consideradas com êxito, pela controladora) de dados e metadados no disco virtual, ocorreram corretamente.
VD Not Consistent
VD Not Consistent significa VD não consistente e indica que a controladora não pode garantir se um arranjo ou disco virtual está íntegro.
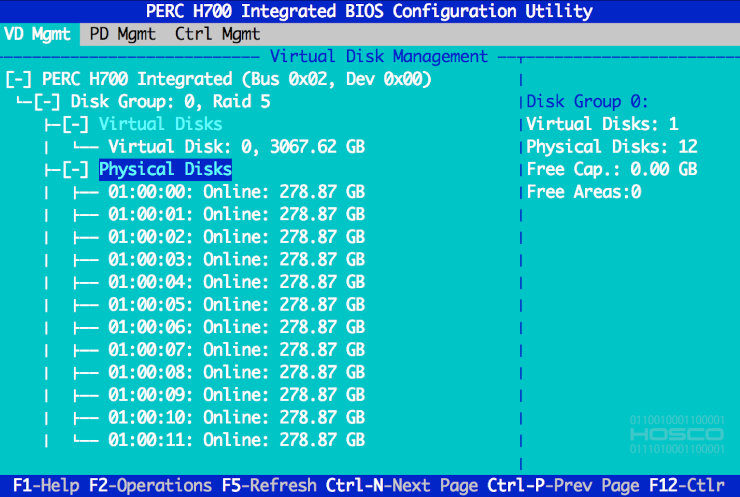
Formatos
DDF
De acordo com as normas da Storage Networking Industry Association (SNIA), as características do RAID devem estar descritas em uma estrutura de metadados localizada ao final de cada dispositivo que participa do array. Esse padrão de metadados, recomendado pela SNIA, chama-se Disk Data Format (DDF). Alguns fabricantes de controladoras também usam o termo Configuration on Disk (COD).
A estrutura de metadados do tipo DDF também é chamada de superbloco. Ele contém informações como o tamanho do array, quantidade de discos, GUIDs etc.
O padrão DDF deveria ser seguido por todo mercado. Mas isso nem sempre acontece e existem fabricantes que criam e adotam formatos proprietários.
MD
Implementação de RAID baseada no driver MD do kernel Linux. A localização dos seus metadados varia de acordo com a versão de seu superbloco e não segue, necessariamente, as convenções da SNIA. Nas versões 0.9 e 1.0, os superblocos ficam no começo do discos. Nas versões 1.1 e 1.2 os superblocos estão localizados no final dos dispositivos.
Adaptec
AMF (Adaptec Metadata Format) e HostRAID.
Highpoint
HPT370, HPT372 e toda a série RocketRAID.
Intel
IMSM (Matrix) e RST (Rapid Storage).
LSI
LSI Data Format (LDF) em placas MegaRAID.
NVidia
Nvidia nForce RAID ou nvraid (MCP, etc.).
Promise
Promise FastTrack (chip PDC20378, etc.).
Silicon
Linha Silicon Image Medley RAID IDE/ATA.
VIA
Série VIA VT8237 RAID (VIA Technologies).
JMicron
Chips da família JMB360 (JMB366, etc.).
Implementações
Hardware
RAID por hardware, igualmente conhecido como Hardware RAID é um arranjo de dispositivos de armazenamento, implementado por meio de uma controladora com firmware responsável por distribuir os dados entre os discos do RAID, bem como, gerenciar seu funcionamento.
Uma vantagem importante do RAID por Hardware é a economia de recursos no sistema operacional do host em razão de todo processamento referente ao array ser feito por uma controladora. Também possuem cache interno e bateria para fornecer energia temporária para a memória cache, em caso de falha ou ausência de eletricidade. Outro benefício é a maior facilidade de gerenciamento do RAID, através de uma interface gráfica ou linha de comando (cli) que permite ao usuário realizar operações de criação, configuração e gerenciamento do RAID.
As desvantagens do RAID por hardware, estão relacionadas aos gastos elevados com controladoras, hardwares específicos e equipamentos adicionais. Há também ressalvas por serem soluções proprietárias e de código fechado, sendo muito difícil identificar o modo de distribuição de dados, entre outras informações.
Controladora
Formalmente denominada disk array controller, pode ser um placa (conectada ao servidor ou storage, através de um slot ou cabo) ou um chip SoC (integrado a placa mãe do servidor, computador ou storage). Os arranjos com chip integrado recebem o nome de ROMB que significa Raid On MotherBoard.
Fabricantes
3ware
A 3ware teve sua fundação em 1980 e foi pioneira em fabricação de controladoras RAID. Ao fim da década de 90 e começo de 2000, conquistou boa parte do mercado de usuários finais, vendendo, inclusive, placas RAID para HDs IDE. Foi comprada pela AMCC e depois pela LSI.
Adaptec
Adaptec, atualmente, pertence a Microchip Technology e foi muito influente no mercado de controladoras SCSI e RAID. Suas placas possuem Adaptec Storage Manager (ASM), uma ferramenta projetada para usuários configurarem e monitorarem os arranjos de discos.
Broadcom
Broadcom é uma das maiores fabricantes de chips para controladoras RAID, integrando placas da Dell, HP, Lenovo, Supermicro e outros fabricantes. Na última década, as Broadcom comprou grandes empresas de armazenamento da dados, como a LSI e Brocade Communications Systems.
Dell
Dell Technologies produz as próprias controladoras RAID sob a marca PERC (PowerEdge RAID Controller) para seus servidores da linha PowerEdge; H730 e H740 são exemplos de placas PERC. A maioria delas são equipadas com chipsets LSI ou Broadcom.
Fujitsu
Fujitsu possui a linha RAID Controller que equipa sua série de servidores Primergy, que prometem elevado desempenho e proteção de dados para ambientes corporativos e data centers. Igualmente, produz a linha ETERNUS RAID Controller.
Intel
Intel produz a linha Integrated RAID Modules com chips ROMB (Intel Matrix RAID em placas mãe de desktop), a série RS3 (servidores e storages em nível corporativos) e a série RMS3 (sistemas de armazenamento escaláveis e de alto desempenho).
HPE
Hewlett Packard Enterprise produz suas próprias controladoras RAID Smart Array para a família de servidores ProLiant e outras soluções de armazenamento. Também fabrica a série HPE Smart SAS Expander Card, que serve para expandir capacidade de armazenamento.
IBM
IBM fabricou controladoras RAID para até 2013 (antes de vender sua divisão de servidores para a Lenovo). Os modelos M1015, M5014 e M5015 são voltados para ambientes mid-end. A linha ServeRAID oferece alto desempenho e confiabilidade para ambientes enterprise e e data centers.
LSI
Logic Storage Interface criou a tecnologia MegaRAID, que engloba controladoras e soluções para gerenciamento de RAID. Tem parceria com a Dell (fornecendo chips para as controladoras PERC), HP, IBM, Supermicro, IBM e NEC. Foi adquirida pela Broadcom, em 2013.
Ciprico
Ciprico foi uma empresa especializada em controladoras SCSI e RAID para aplicações de alta performance e seus produtos eram comercializados sob a marca RAIDCore. Suas placas usavam o poder de processamento dos servidores para melhor gerenciamento dos arrays de discos.
Mylex
Mylex produziu uma das primeiras séries (DAC960) de controladoras RAID dedicadas à ambientes empresariais e foi responsável pela popularização do RAID-5. Ela fornecia controladoras para grandes empresas fazerem rebranding. Foi comprada pela IBM, no ano de 1999.

Software
RAID por software, igualmente chamado de Software RAID ou Soft RAID, é um arranjo de dispositivos de armazenamento implementado por meio de software, em que a distribuição dos dados na camada RAID é gerenciada pelo sistema operacional, um programa ou driver.
Praticamente todos os sistemas Unix oferecem uma solução nativa de RAID. Em Linux, o suporte às matrizes de discos existe em nível de kernel - que é muito vantajoso devido a performance - e o gerenciamento acontece por meio da ferramentas que já estão contidas na instalação do sistema. FreeBSD suporta várias implementações de Soft RAID, como o GEOM - que está embutido no kernel. Solaris conta com o Solstice DiskSuite. Em HP-UX usa-se o VxVM (Veritas Volume Manager) para gerenciamento de RAID, embora LVM seja a tecnologia padrão para configurar conjuntos de discos. Recentemente, muitos dos sistema Unix adotaram RAID-Z (RAID ZFS) como padrão de armazenamento.
O menor custo é, certamente, a principal vantagem deste tipo de implementação, a qual não há necessidade de controladoras caríssimas, hardware dedicado ou storages de grife. Maior controle sobre o arranjo, facilidade de migração e escalabilidade do ambiente, são outros benefícios interessantes. O RAID por software também pode suportar uma quantidade muito grande de discos.
Dentre as desvantagens do soft RAID, devemos mencionar o maior processamento no servidor ou storage. A dificuladade de gerenciamento é um outro inconveniente, frequentemente, mencionado por muitos administradores.
Recomenda-se que neste tipo de RAID haja comunicação direta dos drives físicos, através de controladoras do tipo HBA ou com suporte a pass-through.
Tecnologias
RAID-Z
RAID-Z é uma avançada tecnologia RAID, integrada ao sistema de arquivos ZFS, que disponibiliza armazenamento de nível corporativo sem necessidade de equipamentos específicos, dedicados ou de alto custo. É um subsistema de armazenamento avançado que foi desenvolvido pela Sun Microsystems, em 2005, e lançado em uma das atualizações do Solaris 10.
A configuração e gerenciamento de um RAID-Z ocorre de forma bem simples. Com um comando zpool create é criado um RAID operante (com sistema de arquivos montado e pronto para uso) e com o comando zpool stat é exibido o estado de funcionamento do arranjo. Esta praticidade é um dos principais atrativos para o usos desta plataforma.
O RAID-Z usa stripes de largura variável, sendo imune ao fenômeno write hole error em que o arranjo torna-se inconsistente após uma operação de escrita incompleta. É, portanto, muito seguro e recomendado para ambientes críticos e que necessitam de alta disponibilidade. Além disso, ele agrega todos os outros benefícios da tecnologia ZFS, como snapshot nativo, auto reparo, checksum de dados, etc.
Este tipo de arranjo oferece altas performances se o ARC (cache primário) e L2ARC (cache secundário) estiverem devidamente configurados e usando dispositivos SSD, NVMe, cache drive, que suportam IOPS elevado.
Configurações
RAID-Z1
O RAID-Z1 tem dados e paridade distribuídos em stripes nos dispositivos de armazenamento, de forma parecida com RAID-5. No entanto, não usa blocos de tamanho fixo, mas faixas de dados com dimensão variável que dão maior segurança e previnem contra write hole error. A performance do RAID-Z1 é superior ao RAID-5, assim como, seu tempo de reparo também é mais rápido. Esta configuração oferece paridade única (single-parity) e resiste a falha de apenas um disco físico.
RAID-Z2
O RAID-Z2 possui dupla paridade (double-parity) e seus dados são distribuídos em stripes gravados nos drives de armazenamento, de forma semalhante ao RAID-6. Mas, assim como na configuração 1, os stripes (faixas) têm tamanho dinâmico que garante maior disponibilidade e confiabilidade ao arranjo. O RAID-Z2 tende a maior em relação ao tradicional RAID-6 e sua performance no reparo do arranjo também pode ser superior. Este tipo de arranjo suporta queda de até dois discos.
RAID-Z3
O RAID-Z3 é a configuração básica de armazenamento mais segura e resiliente que existe na plaforma ZFS. Este alto grau de confiabilidade é possível porque o RAID-Z3 usa tripla paridade (triple-parity), garantindo que o arranjo suporte falha de até três dispositivos. Esta sistema de armazenamento é recomendado para storages que guardam informações muito críticas e que devem entregar uma boa performance.
Mirror
A configuração Mirror ou Mirroring constitui um espelhamento parecido com RAID-1, a qual dois ou mais discos têm seus conteúdos replicados, provendo boa resiliência ao storage. Os dispositivos podem estar em controladoras separadas e podem ter capacidades diferentes. A implementação e administração deste tipo de array é bastante simples.
Híbrido
É possível aninhar configurações distintas de RAID-Z, da mesma forma que se faz no RAID convencional. Por exemplo, a união de dois mirrors gera um arranjo parecido com RAID-10. Outro exemplo é o espelhamento de dois arranjos RAID-Z1 criando uma matriz parecida com RAID-50.
BTRFS
BTRFS (B-Tree File System) é uma solução de storage similar ao ZFS, oferecendo checksum, snapshot, gestão de volumes, RAID nativo, etc. Entretanto, o BTRFS escreve seus dados em formato de extents, em vez de blocos. Além disso, possui o verificador de integridade denominado btrfsck.
É uma tecnologia com especificidades de segurança ideais para rodar em cenários críticos: auto recuperação e correção de dados em tempo real. Atualmente, suporta RAID-0, RAID-1, RAID-10, RAID-5 e RAID-6; porém, os níveis 5 e 6 ainda não são recomendados para ambientes em produção.
O desenvolvimento do B-Tree File System é mantido por grandes empresas (Meta, Suse, Red Hat, entre outras), por isso sua adoção tem crescido, em ambientes corporativos, ao longo dos últimos anos.
MD
MD RAID, também conhecido como RAID MD (Multiple Devices), é um subsistema de armazenamento presente no kernel de distribuições Linux e constitui a mais famosa tecnologia de RAID baseada em software. Sua interface para criação, gerenciamento e manutenção é o consagrado utilitário mdadm.
A maioria dos appliances NAS de baixo custo usam RAID MD combinado com LVM (gerenciador de volumes lógicos padrão do Linux) e um sistema de arquivos EXT4 ou XFS. Similarmente, grande parte dos appliances mid-end usam este mesmo sistema. Esta configuração é muito comum em equipamentos Qnap, Synology, Seagate, Asustor, entre outros.
O sistema MDRAID permite gerar arrays com os níveis padrão RAID-0, RAID-1, RAID-4, RAID-5 e RAID-6, bem como, os arrays híbridos RAID-10, RAID-50, dentre outros.
Vinum
Vinum Volume Manager foi o primeiro gerenciador de volumes e RAID, integrado em sistemas da família BSD. Seu desenvolvimento teve inspiração no Veritas Volume Manager, sendo inserido, em 1998, no FreeBSD e NetBSD. Ele consiste, basicamente, em módulo de kernel que cria discos virtuais do tipo RAID-0, RAID-1 e RAID-5; além de permitir a combinação entre eles.
Ao longo do tempo, o vinum foi substituído por soluções mais modernas, como o GEOM, Bioctl, ZFS e HAMMER (DragonFly), e parece ser pouco usado na atualidade.
VxVM
Veritas Volume Manager, lançado em 1993, foi um inovador produto para gerenciar armazenamento em ambientes computacionais. Sua primeira versão oferecia capacidade de gerenciamento à RAID-0, RAID-1 e volumes lógicos; além de recursos muito avançados para aquela época (operações online de expansão ou redução de volumes e migrações de dados sem necessidade de desligar o sistema ou interromper serviços).
GEOM
GEOM é uma estrutura de armazenamento presente no FreeBSD e usada para implementação de soft RAID. Ela é qualificada como "modular" porque é composta, basicamente, por módulos de kernel que são responsáveis pelo funcionamento dos arranjos.
Com o advento do ZFS, o uso de RAID convencional começa entrar em desuso no FreeBSD. Mas ainda há um número expressivo de ambientes usando GEOM com matrizes convencionais.
Módulos
- Geom_raid
- Suporte básico à RAID
- Geom_ccd
- RAID-0 e RAID-1, legado
- Geom_vinum
- RAID-0/1/4/5 legado
- Geom_stripe
- Suporte para RAID-0
- Geom_mirror
- Suporte para RAID-1
- Geom_raid3
- Suporte para RAID-3
- Geom_raid5
- Suporte para RAID-5
- Geom_concat
- Funcionalidade de JBOD
Bioctl
Bioctl é uma plataforma para implantação de RAID e uma interface para gestão de volumes, pertencentes aos unixes OpenBSD e NetBSD. É um subsistema de armazenamento, criado em 2005, que tem como base o módulo bio.
DiskSuite
Online: DiskSuite foi um programa gerenciador de volumes, lançado em 1991, pela Sun, para ser usado no SunOS. Foi a solução pioneira de software RAID e permitia, basicamente, a configuração de RAID-0 e RAID-1. Posteriormente, teve seu nome mudado para Solstice DiskSuite e Solaris Volume Manager ou SVM.
Fake
História
No início dos anos 2000, são lançadas uma série de placas-maẽs para desktop e servidores baratos, contendo interfaces IDE, SCSI ou SATA, capazes de fornecer um sistema RAID. A linha hostRAID, da Adaptec, foi uma das pioneiras em fake RAID, bem como alguns produtos da Promise Technology e HighPoint. Mais recentemente, a RST (Rapid Storage Technology) e Intel Matrix passaram dominar esse mercado.
Conceito
Fake RAID é sempre concebido por uma plataforma de fácil configuração e de baixo custo. Na maioria dos casos, são controladores de disco, convencionais, integrados à placas-mães que contém BIOS com rotinas básicas de RAID, que apenas fornecem interface simplória para o usuário criar arranjos, mas não entregam discos virtuais para o host. Portanto, o sistema operacional depende de um driver ou software complementar para mapear e gerenciar o disco virtual.
Todavia esta plataforma não use controladoras RAID autênticas, ela suporta inicialização (boot) de sistemas instalados em partições de discos virtuais.
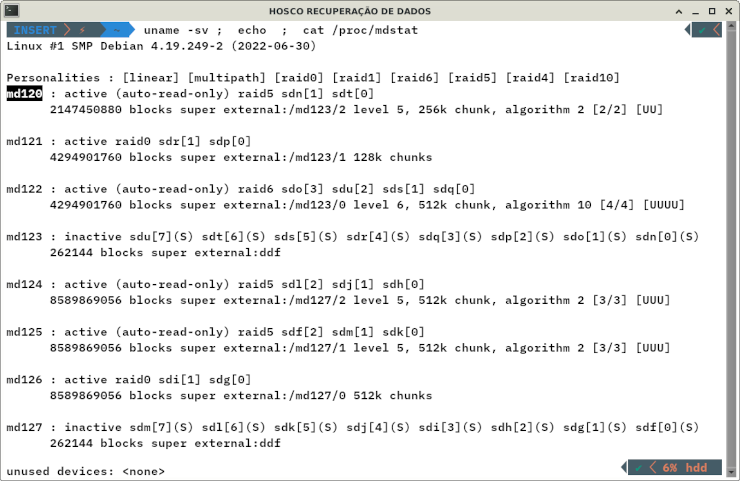
Containers
Container é um grupo de discos gerenciados em um único conjunto, que pode conter vários arranjos RAID, de tipos diferentes, os quais cada arranjo usa discos específicos. É apenas um conjunto de metadados apontando para os dispositivos que de fato integram os arranjos. Por exemplo: um conjunto de 4 discos pode ter um RAID-0, que usa dois dispositivos, e um RAID-1, que usa os outros dois dispositivos.
Análogos
A utilização de unidades integradas como recurso de armazenamento não é exclusivo de RAID e, ao longo da história da informática, existiram outros métodos para juntar ou concatenar dispositivos. Estes, muitas vezes, seguem nenhuma norma relacionada a RAID, usando formas autênticas de alocação.
JBOD
JBOD, abreviação para Just a Bunch of Disks, que significa Apenas um Monte de Discos, é um método simples de armazenamento através de discos concatenados (combinados), sem qualquer tipo de configuração especial, que formam uma unidade virtual cujo tamanho é a soma de todos eles. Os discos são tratados e consumidos de modo independente e sequencial: quando o espaço de um deles acaba o próximo é utilizado para alocar arquivos.
O propósito do JBOD é apenas extensão de capacidade, com nenhuma redundância, disponibilidade ou ganho de desempenho. Sua implementação é simples e rápida, sendo uma solução interessante para um provisionamento rápido de storage - principalmente, em servidores de arquivos temporários.
Algumas controladoras possuem suporte embarcado para JBOD. No entanto, ele também pode ser provisionado sem uso de hardware dedicado, em sistemas Unix que possuem suporte nativo para este tipo de arranjo. Também pode ser configurado em ambientes Microsoft Windows, através de spanned disks, com o LDM.
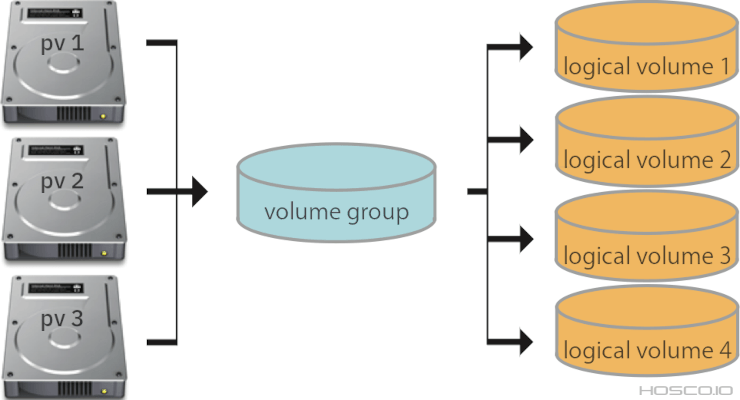
Volume Lógico
Volume lógico é a associação de um ou mais discos físicos em um ou mais volumes virtuais, com propósito de oferecer maior capacidade, eficiência e flexibilidade de armazenamento. Todos os sistemas Unix-like têm suporte nativo a esta tecnologia e o gerenciador de volumes lógicos mais conhecido é o LVM que faz parte distribuições Linux.
A forma de escrita dos dados em um volume lógico pode ser linear, espelhado (mirror) ou distribuído (stripe). No modo linear, as informações são gravadas de forma a ocupar um disco por vez. No modo espelhado, os dados são replicados entre os discos. No modo distribuído, os dados são gravados em stripes (faixas), ou seja, são distribuídos em os discos. O LVM permite criar volumes, do tipo stripe, em formato RAID-5.
Os volumes lógicos são sempre gerenciados por software e não há controladoras com suporte a este tipo de recurso.
Disco Dinâmico
Disco dinâmico é uma técnica de armazenamento, criada pela Microsoft, muito parecida com volume lógico dos sistemas Unix. O seu gerenciamento é feito pela ferramenta LDM (Gerenciador de Disco Lógico).
Os tipos de discos dinâmicos também são muito semelhantes aos usados nos volumes lógicos, sendo eles: spanned (estendido), mirror (espelhado) striped (distribuído) ou RAID-5.
História do RAID
Idealização
No início dos anos 70, inicia-se a informatização das cadeias de produção e serviços, principalmente nos países industrializados. Ascende a necessidade por sistemas de armazenamento digital mais seguros, com alta disponibilidade e de maior capacidade. Os mainframes, que eram os grandes computadores da época, usavam o conceito SLED, o qual um único disco rígido era usado para alocar dados. No entanto, era comum o volume dos dados de uma empresa ultrapassar a capacidade dos maiores HDs que existiam naquela época; além disso, estes discos rígidos não eram rápidos o suficiente e eram vulneráveis à falhas.
Por volta de 1975, a Geac Computer Corporation inicia o desenvolvimento do Geac 8000, um sistema computacional de múltiplo acesso a dispositivos de armazenamento e com alguma proteção contra perda de dados. Ainda neste período, seus fundadores, Gus German (Robert Angus) e Ted Grunau, discutem, pela primeira vez, o uso de discos redundantes e batizam a ideia com o nome de MF-100.
Em 1976, a Tandem Computers lança os servidores NonStop que proporcionavam tolerância a falhas através de um conceito precoce de RAID 1. No ano de 1977, A IBM apresenta uma recurso de storage que mais tarde seria chamada de RAID nível 4. Em 1983, a DEC insere discos rígidos RA80 e RA81, em modo espelhado (que mais tarde seria chamado de RAID 1), em seus storages HSC50. Em 1986, a IBM registra patente para o que chamaríamos de RAID-5.
Em 1987, na Universidade da Califórnia, David Patterson, Garry A. Gibson e Randy H. Katz, criam o termo RAID. No ano seguinte, estes estudiosos demonstram na conferência da SIGMOD (Special Interest Group on Management of Data), seu trabalho chamado A Case for Redundant Arrays of Inexpensive Disks (RAID), onde discorrem sobre a evolução na capacidade dos HDs e como a tecnologia RAID poderia melhorar a performance de I/O, segurança e escalabilidade em mainframes e ambientes que guardam dados digitais. Ainda nesse documento técnico, são apresentados os níveis de RAID 0, 1, 2, 3, 4 e 5.
Logo os idealizadores da nova tecnologia trocaram a palavra inexpensive (barato) por independent. Assim, a expressão Redundant Arrays of Inexpensive Disks deu origem a Redundant Arrays of Independent Disks.
Desenvolvimento
Ao final da década de 80, a IBM já estava empregando RAID 5 em seus servidores S/38 e AS/400, bem como outras grande empresas do mesmo segmento já usavam algum tipo de tecnologia RAID em seus produtos.
Em 1993, David Patterson, Garry A. Gibson e Randy H. Katz, com apoio da NASA e DARPA, constroem um protótipo de matriz com 192 discos rígidos. Este experimento demonstrou um as principais caraterísticas de um sistema RAID: mapeamento entre dispositivos físicos e lógicos, redundância, cache, paridade, entre outras. Através deste estudo, eles também caracterizaram o RAID nível 6. Este projeto serviu de base para os sistemas RAID modernos oferecidos por grandes empresas de informática.
Por volta de 1995, o mercado relacionado a RAID começa a ascender de forma relevante. Em 1997, com o advento do ATAPI-4 e Ultra DMA (que permitiam transferências de dados mais rápidas e com menos uso de CPU), são introduzidas no mercado as primeiras placas RAID para slot PCI. Assim, era possível ter acesso aos benefícios da tecnologia RAID, sem precisar de discos SCSI (que eram caríssimos). Os grandes fabricantes de controladoras, como LSI e Adaptec, que até então tinham seus chips diretamente soldados em placas de servidores de média e larga escala, passam a avançar, vertiginosamente, no mercado das pequenas e médias empresas.
Popularização
A versão 3.0 do FreeBSD, lançada em 1998, é a primeira distribuição da família BSD com uma ferramenta para administrar RAID. Trata-se do vinum, um gestor de volumes que permite implementar matrizes nível 0, 1 e 5.
Ainda em 1998, distribuições Linux passam a ter o software raidtools disponível em seus repositórios. Em 2001, é lançado o mdadm, que tomou o lugar do raidtools e tornou-se a principal ferramenta para gerenciamento de RAID em Linux.
No começo de 2000, com o surgimento das controladoras RAID em formato PCI e dos sistemas de RAID por software, o uso de matrizes de discos começa a se popularizar fora dos ambientes enterprise.
Evolução
Originalmente, os níveis mais comuns das matrizes de discos são 0, 1, 2, 3, 4, 5 e 6. Posteriormente, foram criados níveis híbridos como RAID 0+1, RAID 1+0, RAID 50, RAID 60, etc.
Ao longo dos anos, surgiram tecnologias derivadas, inspiradas e análogas ao RAID, como JBOD, volumes lógicos, entre outras. A maioria delas são baseadas em software e não necessitam de controladoras especiais.
Padronização
Na virada para o século 21, já havia um grande mercado em torno dos arranjos de discos. Fazia parte desse nicho os fabricantes de controladoras, fornecedores de servidores, desenvolvedores de softwares, etc. No entanto, não haviam regras para implementação dessa tecnologia e era comum os fabricantes de placas e os desenvolvedores de soft RAID usarem algoritmos distintos.
Em 2004, os níveis e formatos de RAID começaram a ser padronizados pela SNIA através do formato DDF. É criado o primeiro documento com recomendações e especificações técnicas. Dois anos depois, é publicado Common RAID Disk Data Format (DDF) v1.2, contendo correções e revisões da primeira versão. Em 2009, é lançada a versão 2.0 (última, até a data presente).
Mesmo com as padronizações estabelecidas, existem desenvolvedores e fabricantes que criam variações e designs proprietários. Isso acontece não somente em controladoras de discos, mas, também, em soluções de RAID por software - por exemplo, as últimas versões do mdadm instalam superblocos em áreas de disco que não correspondem às recomendações da SNIA.
Considerações
As soluções modernas de RAID alcançaram um alto grau de maturidade, possibilitando implantação de ambientes muito confiáveis e com alto rendimento. Problemas que pareciam não haver resolução, como inconsistência de paridade, foram resolvidos por soluções software RAID que garantem atomicidade de escrita através de copy-on-write (COW). Em compensação, plataformas hardware RAID ficaram mais robustas, por meio de controladoras com alto poder de processamento e diversos recursos.
Apesar dos consideráveis avanços, ainda há desafios pertinentes ao desempenho de RAID, em alguns cenários específicos, e a maior adoção dos padrões da SNIA por parte dos fabricantes e desenvolvedores.
Devemos enfatizar que não existe ambiente totalmente imune a incidentes, ainda que os principais níveis de RAID proporcionem maior segurança de armazenamento. Portanto, ambientes que guardam informações importantes devem ter soluções ativas de backup e disaster recovery.