
S.M.A.R.T.
Criado em 10/07/2024 por Hosco.
Introdução
A invenção do HD (disco rígido) representou um grande progresso para o armazenamento de dados, por oferecer maior velocidade, permitir acesso direto aos arquivos (DASD) e ser mais seguro que as fitas magnéticas.
Ao final da década de 1960, os discos rígidos já eram amplamente usados em sistemas computacionais de grandes empresas e, frequentemente, alocavam dados críticos. Deste modo, surgiu a necessidade de um sistema embarcado que fornecesse dados sobre o estado de funcionamento dos HDs. A tecnologia SMART resolveu este problema e se tornou o padrão para auto monitoramento de dispositivos modernos, incluindo SSDs e cache drives.
Este artigo abrange desde a concepção do SMART à interpretação de seus parâmetros e marcadores mais importantes.
Histórico
A idealização de sistemas para monitorar o estado de funcionamento em discos rígidos começa na virada dos anos 80 para os 90 do século XX. Em 1992, a IBM lança o inovador sistema de armazenamento 9337 (um storage que equipava computadores AS/400 e acomodava até 7 HDs de 3.5") com suporte a RAID. O HD IBM 0662, que equipava o disk array 9337, foi o primeiro dispositivo de armazenamento a conter um sistema interno de auto-monitoramento, chamado PFA.
Em 1995, a Compaq - em conjunto com Seagate, Quantum e outros fabricantes - concluiu o desenvolvimento do tecnologia IntelliSafe, a qual fazia verificação ativa e constante dos hard disks IDE (Parallel ATA) de notebooks da linha Armada. Na prática, este sistema, embarcado nos dispositivos de armazenamento, media parâmetros de saúde relacionados ao seu funcionamento: tentativas de calibragem, quantidade de setores realocados, entre outros. A obtenção desses dados ocorria através de um software que comunicava com o firmware do HD. O IntelliSafe era bastante confiável e foi reconhecido pelos grupos AT Attachment e Small Form Factors, da ANSI, dando origem ao padrão S.M.A.R.T.
Inicialmente, as padronizações não determinavam métricas ou formas de análise e estavam restritas aos protocolos de comunicação, permitindo que os fabricantes decidissem quais seriam os parâmetros monitorados e quais seriam os limites (contagem de eventos) desses parâmetros. Posteriormente, esta situação foi relativamente normalizada.
Alguns parâmetros de SMART haviam sido incluídos em esboços de revisões do próprio padrão ATA, mas foram removidos antes que a normatização fosse concluída.

Definição
SMART ou S.M.A.R.T. é a sigla para Self-Monitoring, Analysis and Reporting Technology, cuja tradução é Tecnologia de Auto-Monitoramento, Análise e Relatório. Caracteriza-se por um sistema embutido em HDs e SSDs, com função de informar seu estado de funcionamento, reportar ocorrência de falhas e prever situações de inoperância ou dano permanente.
Funcionamento
A tecnologia SMART monitora a atividade do dispositivo de armazenamento para prever incidentes [antes que eles ocorram, de fato]. São analisados parametros como re-allocated sector count, dentre outros, que podem indicar problemas de funcionamento. Também há a comparação de dados referentes a eventos armazenados em logs, além de eventuais rotinas de auto-teste realizadas nos dispositivos.
Para haver funcionalidade, é necessário que o computador ou o sistema operacional tenha um software que, através do devido protocolo, estabeleça comunicação com o SMART e gerencie os dados fornecidos por ele.
A maioria dos BIOS e UEFI têm suporte básico a SMART e exibem alerta durante a inicialização do computador, na eventualizade de um HD ou SSD estar defeituoso ou na iminência de falhar. Em nível de sistema operacional, existem programas mais completos como o GSmartcontrol, CrystalDiskInfo e HD tune. Em ambientes corporativos, os principais fabricantes oferecem soluções robustas que se usam informações do SMART; as quais podemos citar: OpenManage Server Administrator (Dell), Smart Storage Administrator (HPE SSA), Storwize V7000 CLI/GUI (IBM), entre muitos outros.
Principais Atributos
Os atributos SMART de dispositivos ATA usam 1 byte para ID, 2 bytes para sinalizações de status, 1 byte para valor normalizado e 8 bytes para valores específicos do fabricante. Na prática, estes últimos 8 bytes guardam valores comuns (raw values) a quase todos os fabricantes, como worst normalized value (pior valor nomalizado), temperatura, etc. É comum o valor normalizado inicial dos atributos ser 100, entretanto ele pode variar de acordo com o fabricante.
Read Error Rate (ID 01)
Informa a quantidade de erros de hardware que ocorrem durante a leitura de dados nos discos magnéticos (pratos onde os dados são armazenados). Portanto, pode indicar problemas com a superfície dos discos, cabeças de leitura/gravação ou no braço do atuador. Não afeta diretamente SSDs, que podem continuar funcionando, normalmente, mesmo com elevada taxa de erros de leitura. É um dos marcadores mais importantes relacionados com falhas em HDs.
Spin-Up Time (ID 03)
Este atributo exibe a média de tempo que leva para o HD passar de um estado desligado (discos sem rotacionar) para um estado operacional.
Start/Stop Count (ID 04)
Indica uma contagem de ciclos de partida e parada do eixo do disco rígido; cada HD seu próprio número limitado desses ciclos. Um valor de parâmetro abaixo do threshold (limite) demonstra que um disco rígido está defeituoso.
Reallocated Sector Count (ID 05)
Número de setores que foram realocados por apresentarem erros de leitura ou escrita. Esta contagem ocorre quando um setor defeituoso é isolado e seus dados são transferidos para um setor reserva. Um número elevado desses eventos indica problemas na unidade de armazenamento.
Seek Error Rate (ID 07)
Este atributo se refere a taxa de erros de busca e posicionamento das cabeças de leitura/escrita. Pode indicar problemas mecânicos, dano no sistema servo ou nos discos magnéticos. Para alguns modelos de HDs, o aumento no número desses eventos pode não representar um problema.
Power-On Hours (ID 09)
Número total de horas que o dispositivo de armazenamento permanece e/ou permaneceu ligado. Não são contabilizados os períodos que a unidade fica em modo de hibernação. No entanto, alguns modelos da Samsung podem ser configurados para, também, computar os períodos em que a unidade está modo sleep ou idle, através da desativação do recurso DIPM.
Spin Retry Count (ID 10)
Informa o número de novas tentativas de giro dos discos (pratos) para atingir a velocidade (RPM) adequada de funcionamento. Portanto, este evento ocorre após uma tentativa malsucedida para iniciar ou estabilizar a rotação do(s) disco(s) de um HD. Sinaliza danos mecânicos na unidade de armazenamento.
Calibration Retry Count (ID 11)
Este atributo indica a contagem de pedidos de recalibration (recalibração) realizados pelo firmware do HD, considerando que houve uma tentativa anterior malsucedida. O aumento nos valores desse parâmetro indica falha mecânica do dispositivo.
Power-On Count (ID 12)
Este atributo relata o número cumulativo de ciclos de ativação/desativação do equipamento, incluindo os casos de desligamento repentino e desligamento normal.
Soft Read Error Rate (ID 13)
Informa a quantidade de erros de leitura que não puderam ser reparados por ECC (Error-Correcting Code).
SSD Wear Leveling Count (ID 173)
Este atributo relata o número médio de ciclos de apagamento por bloco, em um SSD. Este marcador destina-se a ser um sinalizador de desgaste iminente.
Wear Leveling Count (ID 177)
Este é um atribuito exclusivo de SSDs, que mostra o número de operações de programação e apagamento de mídia (o número de vezes que um bloco foi apagado). Está diretamente relacionado com o tempo de vida do SSD.
Total Used Reserved Block Count (ID 179)
Exibe o número de blocos de reserva que já foram usados para resolver problemas de leitura, escrita ou apagamento. Os valores são relacionados com o attributo Reallocated Sector Count e podem variar de acordo com a densidade do SSD.
Total Program Fail Count (ID 181)
Esse atributo é inerente às unidades SSDs e representa uma contagem total do número de solicitações de gravações malsucedidas.
Total Erase Fail Count (ID 182)
Este é um atribuito exclusivo de SSDs e mostra a contagem total das requisições de apagamento que apresentaram falha.
Runtime Bad Block (ID 183)
Pode indicar o número de reduções na velocidade do link ou largura de banda (de 3 Gb/s de 1.5 Gb/s, por exemplo). Também pode ser a contagem de blocos de dados com erros detectados e incorrigíveis encontrados durante a operação normal. Esse marcador sinaliza a degradação da unidade ou possíveis problemas eletromecânicos. É um atributo exclusivo da Seagate, Samsung e Western Digital.
Reported Uncorrectable Errors (ID 187)
Este atributo mostra a quantidade de erros que não puderam ser recuperados usando o ECC de hardware.
Air Flow temperature (ID 190)
É um atributo exclusivo para SSDs e informa a temperatura atual da área ao redor dos chips NAND.
ECC Error Rate (ID 195)
Este atributo exibe o índice de erros corrigíveis de ECC.
Reallocation Event Count (ID 196)
Mostra a quantidade total de operações de remapeamento (realocação), incluindo aquelas que não tiveram sucesso. São as tentativas de transferir daddos de setores realocados para a área de setores reserva.
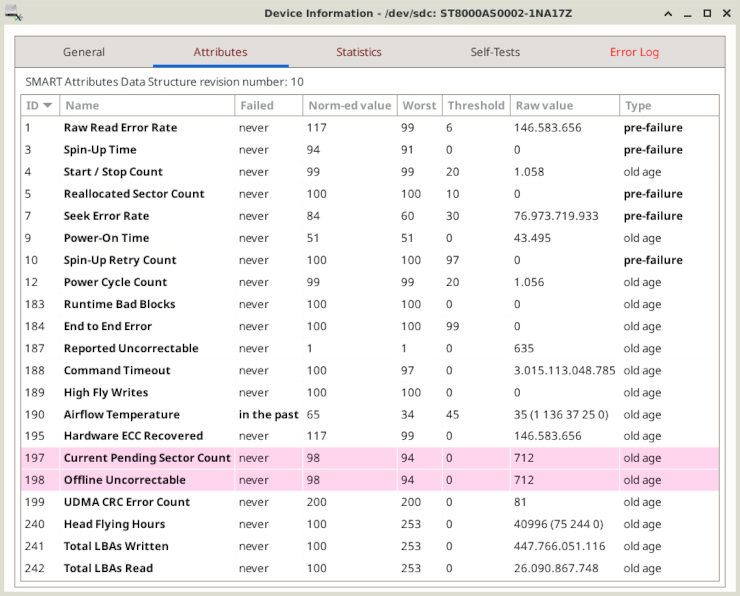
Current Pending Sector Count (ID 197)
Quantidade de setores instáveis que tiveram erros de leitura, incorrigíveis, e que aguardam para serem remapeados (realocados). Um elevado número de setores instáveis pode ser sintoma de degradação dos discos magnéticos ou problemas nas cabeças de leitura, indicando que o dispositivo precisa ser substituído.
Offline Uncorrectable Sector Count (ID 198)
Número total de erros incorrigíveis durante a leitura ou gravação de um setor. O aumento no valor desse atributo pode indicar defeitos na superfície do disco ou problemas mecânicos.
CRC Error Count (ID 199)
Quantidade de erros de verificação de redundância de ciclo (CRC). Em caso de problemas entre o host e um chip NAND ou DRAM, o mecanismo CRC registrará o erro e o armazenará nesse atributo.
Multi-Zone Error Rate (ID 200)
Este parâmetro indica a quantidade de erros de gravação em setores está bastante relacionado com a condição física da unidade de armazenamento.
Soft Read Error Rate (ID 201)
Este atributo relata a qauntidade total de erros soft read incorrigíveis.
Power Recovery Count (ID 235)
Contagem do número de casos de desligamento repentino em que o firmware do dispositivo, na inicialização subsequente, recuperou os dados do dispositivo - incluindo aqueles relacionados a remapeamento.
Total LBAs Written (ID 241)
Este atributo é considerado apenas informativo pela maioria dos fabricantes. Ele pode sinbalizar o envelhecimento do equipamento ou possíveis problemas eletromecânicos, mas não indica, diretamente, uma falha iminente do mesmo.
Read Error Retry Rate (ID 250)
Este atributo mostra a quantidade de erros ocorridos durante a leitura de um determinado setor.
Free Fall Protection (ID 254)
Exibe o número de Free Fall Events (Eventos de Queda Livre) detectados pelo accelerometer sensor (sensor de acelerômetro).
Software
Existem programas de gerenciamento de SMART para todos os sistemas operacionais conhecidos. Em alguns casos, são ferramentas nativas do próprio sistema. Abaixo, segue uma lista com alguns desses softwares.
Windows
Linux
macOS
BSD
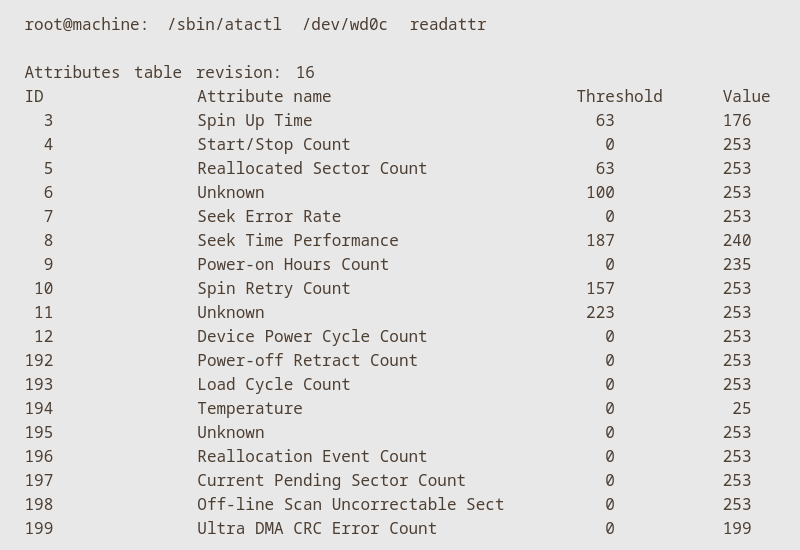
Conclusão
A melhor forma de monitorar unidades de armazenamento é por intermédio da tecnologia SMART. No entanto, alguns limites de valores de parâmetros podem ser distintos, variando de acordo com modelo e fabricante. Por isso é importante consultar documentações ou delegar o gerenciamento para sistemas ou programas apropriados.
Por fim, cabe salientar a importância do uso de sistemas de backup para evitar problemas com a inoperabilidade abrupta de dispositivos de armazenamento.