
RECUPERAÇÃO EM STORAGE
RECUPERAÇÃO DE DADOS EM STORAGE DE MULTIPLAS ESCALAS
SERVIDORES E APPLIANCE DE VÁRIOS TIPOS E FABRICANTES
REVERSÃO DE INCIDENTES EM SISTEMAS DE ARMAZENAMENTO

NOSSO
DIFERENCIAL
AUTORIDADE
Histórico consistente em recuperar dados de storage NAS e SAN
QUALIFICAÇÃO
Analistas certificados LPIC, MCSA, LinuC/LPI-Japan e demais
EFICIÊNCIA
Eficácia na recuperação de dados em sistemas de armazenamento
ESCALABILIDADE
Suporte a ambientes enterprise com mais de 96 drives (HD/SSD)
ANALISTAS
QUALIFICADOS
Equipe certificada LPIC/1Z0-414/MCSA, com 20+ anos de experiência em reconstruir RAID, acessar volumes com danos e reparar HDs em servidores de armazenamento.
ESTRUTURA
AVANÇADA
Ambiente Classe 100 e equipamento MRT para reparos em HDs, CPD proprietário com suporte para sistemas enterprise e soluções autorais eficientes (RAID/ZFS/LV Recovery).
PLATAFORMAS SUPORTADAS

SERVIDOR/STORAGE
Reversão de incidentes em storage e servidores, incluindo recuperar dados de SAN e sistemas (Unix ou Windows) configurados para armazenamento.

APPLIANCE
Ações em appliance com discos danificados ou falhas em camadas lógicas, recuperação de dados em NAS e equipamentos com tecnologias proprietárias.
ARQUITETURAS SUPORTADAS

NAS e SAN
Soluções eficientes para recuperar dados de storage com acesso em nível de arquivos (NFS, SMB, CIFS) e de bloco (LUN provida por Fibre Channel ou iSCSI).

DAS
Restauração de arquivos e reparo de camadas lógicas em servidores com armazenamento por conexão direta a dispositivos SAS, SCSI, SSA, SATA e IDE.
SISTEMAS ATENDIDOS
O serviço de recuperação de storage atende sistemas de armazenamento de diferentes fabricantes, gerações e níveis de complexidade; incluindo plataformas dedicadas à cenários corporativos com múltiplos discos, controladoras, arrays e volumes. Estão inclusos ambientes bare metal e virtualizados (VMware, Proxmox, Xen, Hyper-V, PowerVM, etc.).
A atuação técnica envolve reverter falhas lógicas e físicas em HDs ou SSDs, possibilitando o reparo de estruturas de dados e componentes associados ao armazenamento. Estão inclusos reparos em estruturas virtualizadas (Xen, VMware, Hyper-V, LPAR, etc.).
Esta seção contém os principais fabricantes e sistemas suportados pelo serviço de recuperação da Hosco.
A engenharia aplicada também contempla topologias de rede integradas, incluindo capacidade para recuperar NAS em ambientes contendo arquivos compartilhados, bem como para recuperar SAN.
Dell PowerVault
MD32, MD34, ME4, ME5 e 210S ▼
- MD3200, MD3220, MD3400, MD3420
- MD3460, ME4012, ME4024, ME4084
- ME5212, ME5224, ME5284, 210S
Dell PowerEdge
Servidor de Rack/Torre com PERC ▼
- R330, R410, R620, R630, R710, R720
- R730, R740, R760, T130, T140, T150
- T310, T320, T330, T340, T440, T620
HPE Storage
Disk Arrays MSA com RAID e JBOD ▼
- MSA 1000, 1040, 1042, 1060, 1500
- MSA 2040, 2042, 2060, 2062, 2070
- MSA2000, MSA P2000, D2600, D3600
Servidores HPE
Proliant DL/ML, Apollo e Integrity ▼
- ProLiant DL180, DL360/DL380/DL385
- DL580, ML110, ML150, ML350/ML370
- Apollo 4200/4500, Integrity linha RX
IBM RS/POWER
Servidores RISC System e POWER ▼
- RS/6000 7025/26 F50/H70, 7015, S7A
- S80, 44P 170/270, pSeries 610-680
- Serial Disk System SSA 7133-D40/T40
IBM DS/HS/EXP/X
DS, Storage Expansion Unit e X ▼
- DS3000/DS4000/DS5000, HS20-HS22
- EXP3000, EXP4000, EXP710, EXP810
- System x3400, x3500, x3550, x3650
Oracle Storage
Sun StorEdge/StorageTek e Axiom ▼
- StorEdge 3510/3310, 6140, T3, A1000
- StorageTek 2540, 2530, 6180, 2510
- Pillar Axiom 600, Sun Storage 6130
Servidores Oracle
Sun Fire X/T-Series, Oracle X-Series ▼
- Sun Fire X4200, X4170, X4100, X4270
- Oracle Server X3-2, X4-2, X5-2, X6-2
- Sun Fire T2000, T5120, T5220, X2200
Dell EMC
VNX 5000, VNXe 3000 e ClariiON ▼
- VNX 5100, 5200, VNXe 3100, 3200
- ClariiON CX300/CX500/CX3-10, AX4-5
- CX4-120, AX150, CX3-20, CX4-240
Supermicro
SuperStorage/Server, Twin e Ultra ▼
- SuperStorage 6049, 6048, 5049, 2029
- SuperServer 6029, 6019, 2029, 5019
- Twin 6028, BigTwin 6029, Ultra 2029
Lenovo
ThinkSystem, System X e Lenovo ▼
- SR650, SR550, SR630, SR530, SR590
- x3650 M5, x3550 M5, RD650, RD550
- S3200, S2200, DE4000H, DE2000H
NetApp
Disk Arrays FAS2000 e E-Series ▼
- FAS2240, FAS2520, FAS2550/FAS2720
- E2600, E2700, E2800, E5400, E5500
- E5600, E5700, E2624, E2724, E2824
Hitachi Vantara
HDS AMS e HUS / VSP G-Series ▼
- AMS500, AMS2100, AMS2300/2500
- HUS 110, HUS 130, HUS 150, HUS VM
- VSP G200, VSP G400, VSP G600, G350
Fujitsu
Primergy RX e TX / Eternus DX ▼
- RX2540, RX2530, RX2540, RX2520
- TX1330, TX2550, TX1320, TX1310
- DX100/DX200 S5, DX60 S5, DX90 S2

Debian / Ubuntu
Linux Debian/Ubuntu e Derivados ▼
- Debian, Ubuntu Server, Proxmox
- Itautec Librix, Open-E JovianDSS
- ZFS/BTRFS, RAID MD e volume LVM
Red Hat / CentOS
Sistemas baseados em Red Hat ▼
- Red Hat Enterprise Linux, CentOS
- Rocky, Veritas Flex 5200 e 5300
- Oracle Linux com ZFS, XFS, LVM

Sistemas BSD
FreeBSD, Open/Net, Dragonfly ▼
- Unix FreeBSD, OpenBSD, OpenBSD
- Dragonfly com HAMMER e HAMMER2
- GEOM RAID, pool ZFS, UFS, FFS

Solaris
Solaris, OpenSolaris, OpenIndiana ▼
- Red Hat Enterprise Linux, CentOS
- Rocky, Veritas Flex 5200 e 5300
- Oracle Linux com ZFS, XFS, LVM
INCIDENTES
ATENDIDOS
Danos em HDs/SSDs SAS, SATA, etc.
Inoperância/Corrupção de Datastore
Falhas elétricas em controladoras
Exclusão de Disk Group, mDisk, etc.
Indisponibilidade e Falhas em RAID
Corrupção em LUNs ou File Share
Interrupções de Rebuild em Arrays
Erro em Pool, Volume e file system
DEPOIMENTOS
VALIDAÇÕES DE ESPECIALISTAS
A credibilidade de nossos serviços é consolidada através de resultados comprovados em situações críticas. Por isso, reunimos avaliações de experientes profissionais de TI (gestores de infraestrutura, arquitetos de soluções, etc.) que acompanharam nossos processos de recuperação em HD envolvendo falhas físicas diversas e perda de dados em ambientes corporativos de alta disponibilidade.
Aqui você encontra relatos de especialistas que testemunharam nossas atuações em casos que demandam expertise técnica para recuperar informações com segurança e restabelecer a continuidade operacional. São depoimentos que evidenciam a integração entre laboratório especializado, equipe qualificada, ferramentas proprietárias e protocolos que fundamentam nossos serviços. Para garantir total transparência, todos estes depoimentos são públicos e estão disponíveis para consulta direta na seção de recomendações contida no perfil LinkedIn do CTO da Hosco.
-

"Trabalhei em fabricantes de armazenamento desde 2008 (Seagate, Western Digital) e sei da complexidade... Enviamos para a Hosco discos de um NAS com RAID corrompido em 2022... A Hosco conseguiu recuperar os dados que precisávamos e sou muito grato a eles."
-

"Recomendo trabalho do William, ele conseguiu a recuperação de dados com a importação do Pool ZFS DATA1 sendo bem sucedida e consequentemente a remontagem do Pool de 24 discos SAS. Ele conseguiu fazer o Impossível."
Sun X4 | Ambiente: 24x HD + SAN + RAID-Z + iSCSI + Oracle VM -

"A Hosco fez a recuperação de dados no RAID do nosso servidor HP (que o ILO reportava falha em alguns HDs) e ainda repararam o datastore com todas as VMs. Tudo intacto. Altamente recomendado!"
HPE Proliant | Ambiente: 12x HD SAS + Datastore + LUNs + VMs
STORAGE
Sistema de armazenamento, popularmente denominado storage, é um equipamento computacional composto por HDs ou SSDs, com a finalidade de armazenar e centralizar informações digitais. A sua conexão ao host pode ocorrer de modo direto ou indireto.
Na arquitetura de acesso direto, os drives respondem a controladoras internas acopladas no host, o qual detém o controle físico e lógico dos recursos. Nas arquiteturas de ligação indireta, o computador se conecta, por rede ou canal de dados, a um sistema de armazenamento autônomo ou a um volume controlado, através de um servidor.

As plataformas de armazenamento indireto centralizam recursos e tendem a garantir alta disponibilidade e maior escalabilidade.
A primeira vertente atua no compartilhamento em nível de sistema de arquivos, permitindo o acesso simultâneo a diretórios comuns via rede por protocolos como SMB e NFS, operando sob estruturas com proteção nativa contra corrupção de dados.
A segunda vertente atende a cenários de missão crítica e máximo desempenho, distribuindo os recursos estritamente em nível de bloco e usualmente por meio de uma infraestrutura de fibra óptica e com maior performance. Essa tecnologia entrega volumes brutos que processam comandos de entrada e saída de baixo nível, simulando discos físicos acoplados diretamente ao servidor para assegurar latência ultrabaixa em cenários com bancos de dados, virtualização, entre outros.

FALHAS
Grande parte dos crashes e desastres com perda de dados em storage decorre da monitoração ineficiente de arrays de discos e da imperícia na interpretação de marcadores preditivos (logs de sistema e alertas de kernel para hardware em condição de pré-falha), principalmente, relacionados a degradação de drives.
Embora rotinas estritas de compliance minimizem riscos, colapsos súbitos afetam até mesmo infraestruturas redundantes. Setores inteiros podem ser paralisados por eventos inesperados de hardware ou erros humanos em janelas de manutenção críticas, exigindo intervenção especializada para a preservação dos dados.
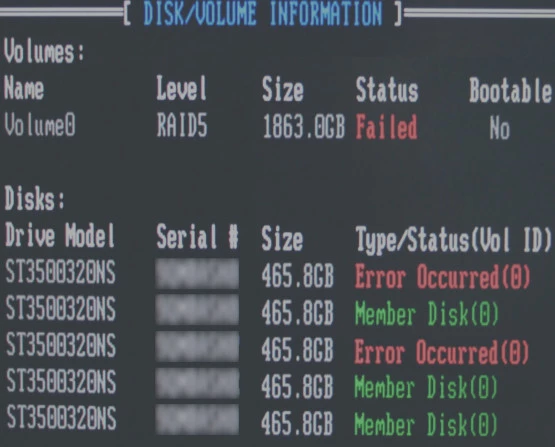
Quando o arranjo entra em estado crítico, os indícios de falha se manifestam por meio de picos anômalos de processamento em serviços de file server (como SAMBA e NFS), overhead em daemons iniciadores (iscsid), congelamento de threads de E/S (I/O) e retenção severa nas requisições do sistema de arquivos. Identificar esses comportamentos de forma precoce é vital para evitar tentativas intempestivas de montagem forçada.
Além dos incidentes físicos e lógicos tradicionais (falhas em processos de rebuild, exclusões acidentais etc.), o ecossistema de alta disponibilidade é vulnerável ao fenômeno do write hole. Essa falha de consistência em operações de escrita assíncrona pode desestruturar algumas tecnologias de RAID. A Hosco foi a empresa pioneira a mapear e tratar tecnicamente esse cenário complexo no mercado de recuperação de dados brasileiro.

SOLUÇÕES
A Hosco consolidou sua eficiência na recuperação de dados em sistemas de armazenamento através de décadas de atuação em cenários enterprise. Dispondo de CPD e profissionais com expertise homologada, a empresa entrega respostas rápidas e metodologias eficientes para restabelecer arquiteturas corporativas de grande porte.
O corpo técnico possui um histórico sólido no gerenciamento de ambientes Unix-like com arranjos complexos, volumes lógicos e partições distribuídas. Essa especialização auxilia no mapeamento de estruturas lógicas e reparo de sistemas de armazenamento.

Os projetos são conduzidos e realizados por analistas experientes em ambientes de missão crítica, qualificados para lidar com dispositivos danificados e preservar a integridade em sistemas de arquivos avançados. A operação ocorre integralmente em laboratório próprio, amparada por infraestrutura com servidores e storage de alta performance, em plataformas seguras e estáveis como IBM, Sun, Oracle e Dell.
Em caso de indisponibilidade de dados, o procedimento recomendado é suspender o uso dos discos para avaliação especializada na Hosco. Principalmente em ambientes críticos, deve-se preservar os dipositivos e evitar inclusive I/O de leitura, priorizando apenas o acionamento de backups isolados, pois intervenções diretas no storage podem comprometer uma posterior recuperação profissional dos arquivos.
