
GESTÃO DE FALHAS EM RAID
Criado em 03/03/2026 por Hosco.
Introdução
RAID offline ou indisponível pode representar uma situação crucial que mobiliza equipes de tecnologia e times de operações em ambientes corporativos. A precisão técnica das decisões tomadas logo após a falha de um array é determinante para o seu restabelecimento e preservação de suas estruturas lógicas.
| Significado | Impacto | Ação Segura | |
|---|---|---|---|
| Active/OK | RAID OK | Sem alerta | Monitorar logs |
| Degraded | Degradado | Risco maior | Isolar falha |
| Resync | Recompondo | Janela crítica | Monitorar status |
| Inactive | Não iniciado | Não ativo | Evitar reparo |
| Failed | Falha | Sem acesso | Interromper I/O |
| Significado | Impacto | Ação Segura | |
|---|---|---|---|
| Optimal | VD/LD OK | Sem alerta | Monitorar logs |
| Degraded | Degradado | Risco maior | Isolar falha |
| Rebuild | Recompondo | Janela crítica | Monitorar status |
| Foreign | Config. ext. | Sobrescrita | Mapear discos |
| Failed | Falha | Sem acesso | Interromper I/O |
| Significado | Impacto | Ação Segura | |
|---|---|---|---|
| Online | Pool OK | Sem alerta | Monitorar logs |
| Degraded | Degradado | Risco maior | Isolar falha |
| Resilver | Recompondo | Janela crítica | Monitorar status |
| Unavail | Inacessível | Indisponível | Preservar vdevs |
| Faulted | Falha | Sem acesso | Interromper I/O |
Com base em nossa experiência de décadas, criamos este documento como uma evolução do nosso Guia para Recuperação de RAID, originalmente publicado em janeiro de 2023. O guia original tornou-se referência técnica no setor - a ponto de ter sua estrutura amplamente replicada por concorrentes. No entanto, a experiência nos mostra que a necessidade mais urgente dos gestores é "o que fazer" para não agravar o problema. Sendo assim, este é um manual técnico com as ações imediatas seguras que podem evitar perda de dados.
Este guia tem o propósito de orientar sobre ações de diagnóstico, contenção e tomada de decisões para proteção de ativos. Para incidentes em RAID/VD/LD com dados críticos, a única ação 100% segura é interromper imediatamente toda a atividade de I/O nos discos.
Suporte a Incidentes Críticos: Falhas lógicas ou físicas em disk arrays podem exigir respostas precisas. A Hosco atua na recuperação avançada em cenários com dados importantes e com necessidade de reação imediata.

Sobre RAID
Definição
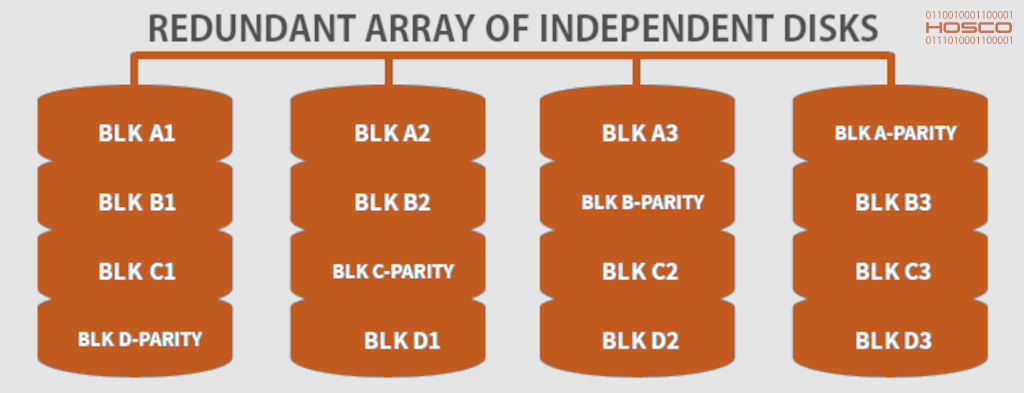
RAID é o acrônimo para Redundant Array Of Independent Disks e trata-se de uma camada de armazenamento, constituída de dois ou mais dispositivos (HDs/SSDs), que proporciona aumento de capacidade e redundância. Em língua portuguesa, às vezes o termo é referenciado simplesmente como arranjo ou matriz de discos. Para melhor compreensão sobre esta tecnologia, indicamos a leitura do nosso abrangente artigo sobre RAID.
Formatos
Os principais designs de RAID com código aberto são DDF, MD e RAID-Z. Já os proprietários, costumam estar em sistemas HPE, 3PAR, Dell, IBM, NetApp e demais que usam controladoras com firmwares especiais.
Incidentes Comuns
Causas Principais
Problemas Físicos
Defeitos em drives de armazenamento (corrompimento em módulos de firmware, danos em cabeças de leitura e gravação, etc.) do RAID e falhas nas controladoras.
Problemas Lógicos
Deleção de dados, corrupção de metadados, formatações, rebuilding indevido, inserção incorreta de discos e outras ações humanas não intencionais ou dolosas.
Etapas da Gestão
Respostas a Falhas
Resposta a incidentes ou resposta a falhas - no contexto de sistemas de armazenamento - é o conjunto de processos (envolvendo pessoas e tecnologias) acionados para detectar, analisar, mitigar e erradicar a causa de uma ocorrência, incluindo a restauração segura dos serviços ou recursos afetados e implementação de medidas preventivas para reduzir a probabilidade de recorrência.
⚠️ Aviso de Dano: É altamanete desaconselhado submeter discos de um RAID inacessível a clonagens por software, escaneamentos ou quaisquer ações com alta carga de I/O. Em arranjos degradados, discos aparentemente funcionais podem conter avarias latentes que, sob estresse, evoluem para uma falha total.
Análise de Eventos
Após a constatação de indisponibilidade de um RAID, a equipe responsável deve coletar informações relevantes ao incidente. É sempre recomendado analisar eventos críticos capturados pelos sistemas operacionais, bem como os logs de firmwares que controlam as camadas mais baixas de storage e as configurações de RAID. Os alertas emitidos por sistemas de monitoramento também deverão ser minuciosamente observados.
LINUX
Tradicional
MD é uma implementação de RAID baseada no driver md do kernel Linux e muito adotada em distribuições tradicionais. Normalmente é combinada com volumes de LVM em servidores de arquivos e datastores midrange. O arquivo /proc/mdstat contém informações de funcionamento dos arrays, sendo que os estados operacionais resyncing, recovering e rebuilding demandam atenção, e failed indica inoperância.
DDF é um padrão de metadados RAID definido e recomendado pela SNIA. A condição de funcionamento destes tipos de arranjos pode ser verificada por inspeção direta nos dispositivos ou por meio do dmraid.
LVM2 suporta RAID com design próprio, além de seus tradicionais VG e LV. A operacionalidade deste tipo de arranjo pode ser checada com o comando lvs -o name,vgname,segtype,lv_health_status,attr.
dmesg e journalctl exibem mensagens de kernel que auxiliam na identificação de HDs ou SSDs danificados. Para um diagnóstico detalhado, analistas experientes executam dmesg combinado com grep ou sed. Um comando eficiente para detectar drives avariados é dmesg | grep -oE "\[sd[a-z]{1,4}\].*(FAILED|Error)".
O comando smartctl -a é seguro para verificar parâmetros do estado de funcionamento (saúde) dos dispositivos físicos. No entanto, self-tests devem ser evitados por causa do risco de causarem danos fatais em discos com estado de pré-falha.
Appliance
OpenMediaVault (OMV) é um conhecido NAS baseado em Debian. Em seu dashboard há colunas Status nas abas RAID Management, Multiple Device, ZFS, Logical Volume Management e File System; a presença de valores Failed, Faulted, Unavail e Errors indicam estados anormais de funcionamento. A respeito da saúde dos discos, a constatação de problemas é verificada pela presença de estados Warning ou Bad dentro do menu SMART.
TrueNAS SCALE também é uma solução bem estabelecida e construída sob Debian. Em Storage Dashboard, a janela ZFS Health deverá ter Pool Status com valor online e Total ZFS Errors com valor 0. A janela Disk Health deverá sinalizar um adequado estado de funcionamento dos drives do pool (Mirror, RAID-Z1, RAID-Z2 e RAIDZ-3). No submenu status dentro de Storage, valores offline e unavail podem indicar avarias nos dispositivos.
Open-E JovianDSS é uma solução enterprise (HA ativo‑ativo, snapshots, proteção on/off‑site, etc.) proprietária com funcionalidade de SAN por iSCSI e FC, usada como Node de cluster. A janela State do seu dashboard pode ter os valores ONLINE, DEGRADED, UNAVAIL ou SUSPENDED, e Status descreve o estado do pool. O menu Scrub Scanner reporta testes de integridade e tentativas de auto-correção realizadas pelo scrub no sistema de arquivos.
PetaSAN é um appliance scale-out que entrega iSCSI target sobre Ceph. O marcador Ceph Health com valor Warning sinaliza problemas que não representam falha iminente; já o valor Error mostra que o cluster possui erros graves que impactam a disponibilidade ou a integridade dos dados. O indicador Ceph Cluster OSD Status contém os quadrados Up (exibe o número de OSDs ativos) e Down (mostra a quantidade de OSDs inativos).
Rockstor e Openfiler também são appliances NAS/SAN desenvolvidos sobre Linux. Ambos possuem interface intuitiva que facilita a análise de eventos relacionados com desastres em camadas de armazenamento.
BSD
Tradicional
Os sistemas da família BSD têm muitos utilitários em comum com Linux, incluindo o dmesg e outros que podem ser usados para diagnosticar problemas em arranjos de discos. Alguns destes estão já integrados na base do sistema, outros (como o smartctl) podem ser instalados através de ports, pacotes ou compilação de códigos-fonte. O dmesg é usualmente concatenado com grep e/ou sed, conforme foi descrito na secção anterior sobre Linux.
Graid status e gmirror status são comandos usados em FreeBSD para exibir operatividade de um RAID; eles suportam diversos formatos de matadados, incluindo o usado pelo subsistema GEOM. Gvinum list é um comando que mostra o estado operacional de arranjos criados com Vinum Volume Manager.
Desde a década de 2010, o ZFS (e seus níveis RAID‑Z1/Z2/Z3) se consolidou como a principal opção para matrizes de discos em ambientes mid-end e enterprise controlados por FreeBSD, OpenBSD e NetBSD; embora as soluções de RAID tradicionais (hardware RAID e GEOM) continuam sendo utilizadas.
Zpool status é um comando da suite de administração do ZFS, que detalha informações dos pools. No rótulo state, valores FAULTED, UNAVAIL e SUSPENDED indicam inoperância do pool em decorrência de erros (que na maioria dos casos estão relacionadas com falhas em vdevs). Em scan, existem informações sobre resilvering (reconstrução) ou scrub (reparo). Em errors, há eventuais registros de corrupção de dados no pool.
Appliance
TrueNAS CORE é um appliance NAS/SAN que roda sob FreeBSD e possui uma interface de gerenciamento com recursos de alerting, reporting e analycs, além de suporte a monitoramento de pools e discos. É um painel web semelhante ao da família SCALE.
XigmaNAS também é um NAS/SAN baseado em FreeBSD e tem seu monitoramento (por webUI) de storage localizado principalmente no submenu ZFS presente em Disks, especialmente nas páginas de Pools, onde é possível verificar a saúde de pools (incluindo sinais de degradação). Dentro de Advanced (no menu System) e Information (dentro de Diagnostc) é possível consultar o SMART dos discos. Para verificar estado de RAID por GEOM, deve-se acessar geom used (Information) em Software RAID (dentro de Disks).
SOLARIS
Tradicional
Os executáveis metastat e metadb fizeram parte do Solstice Disksuite e, posteriormente, do SVM. Trata-se de uma stack original do Sun/Oracle Solaris e que foi herdada pelo OpenSolaris e OpenIndiana.
A saída esperada do comando metastat é State: Okay para o estado do RAID e para cada um dos dispositivos que o compoem. Para o metadb (com parâmetro -i), a saída deve apresentar flags a, u e a; ja as flags M e W indicam problemas.
Em 2006 a Sun anunciou o ZFS incluído no Solaris 10 6/06 (U2); sendo o primeiro sistema operacional com suporte nativo para este file system, muito antes, inclusive, da família BSD. Desde então, arranjos de discos com formato tradicional vêm sendo substituídos, nessa famíla de sistemas, pelo ZFS. Atualmente, este é o file system padrão da família Solaris e usados em storages de diversas aplicações. Assim sendo, Zpool status é o comando que relata informações dos pools. No rótulo state, valores FAULTED, UNAVAIL e SUSPENDED indicam inoperância do pool em por causa de eventos que normalmente estão relacionadas com falhas em vdevs. Os campos scan e errors, também registram informações importantes sobre estados de operatividade.
Appliance
ZFSSA é tanto um NAS quanto um SAN, suportando protocolos de arquivo (ex.: NFS e SMB) e de bloco (ex.: iSCSI e Fibre Channel). Ele tem Browser User Interface (BUI) com uma guia Status que resume o estado geral dos serviços, discos e outros recursos. Detalhes problemas de hardware são obtidos na guia Maintenance.
NexentaStor é um fork (illumos) do OpenSolaris que oferece funções de NAS e SAN; possui uma interface de nível empresarial e com recursos avançados. Ele conta com o NexentaFusion, um servidor de gerenciamento adicional que exibe, na coluna Health, o estado operacional do nodes/appliances registrados e conectados ao equipamento. Ao clicar nestes nodes/appliances, pode-se obter mais detalhes sobre a saúde dos recursos e funcionamento.
STORAGE/SERVIDOR
Dell (iDRAC/PERC/OMSA)
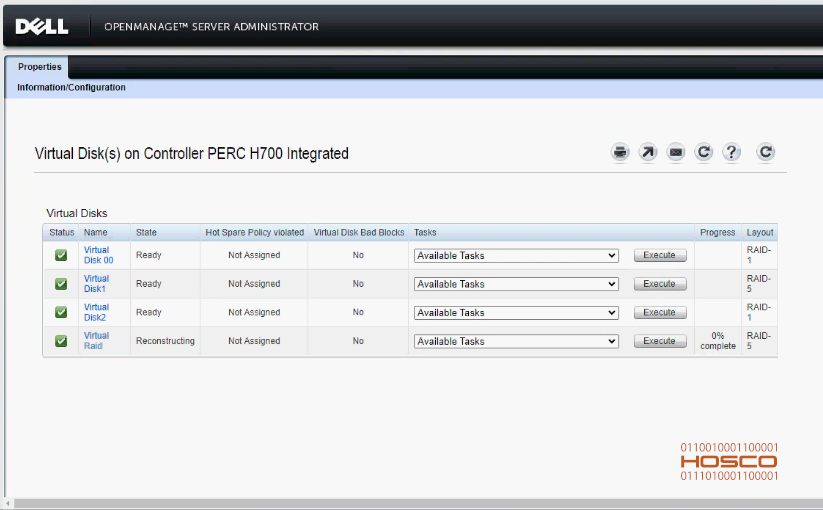
iDRAC contém as seções Storage e Virtual Disks as quais indicam o status dos arrays. Estados como Degraded, Rebuilding ou Resyncing indicam atividade de recuperação; Failed ou Offline sinalizam falha crítica. É importante consultar o Lifecycle Log para obter eventos detalhados, incluindo alertas de software RAID pelo iDRAC Service Module, além de monitorar os discos (S.M.A.R.T.) para Predicted Failure.
PERC possui as seções Virtual Disks e Physical Disks as quais exibem esses mesmos estados. Degraded revela perda de redundância; Rebuilding mostra progresso de reconstrução; Failed confirma inoperância. É essencial verificar o percentual de eventual rebuild, para avaliar integridade dos dados.
OMSA contém o painel Storage > Controllers que consolida status de arrays e discos. Alertas de Predictive Failure ou Critical são destacados; logs detalhados correlacionam falhas físicas com eventos do sistema. É útil para monitoramento contínuo em ambientes corporativos.
HPE (iLO/OneView/Smart Array)
ILO, tem uma aba System Information > Storage que exibe o Health Status dos arrays e controladoras Smart Array. Degraded, Rebuilding ou Predictive Failure são condições que demandam atenção imediata; Failed indica disco ou array inoperante. É importante consultar o IML para identificar causas, como erros corretíveis ou falhas lógicas.
OneView contém a seção Server Hardware > Storage Volumes a qual exibe status agregados de múltiplos servidores. Alertas de Degraded ou Critical são centralizados; dashboards mostram health global e progresso de rebuilds. É útil para ambientes corporativos com gerenciamento centralizado de infraestrutura.
Smart Array é o utilitário da controladora homônima, que tem as seções Array Configuration e Logical Drive Status, as quais revelam estados detalhados. OK (Rebuilding) indica reconstrução em andamento; Failed confirma falha de disco físico.
IBM/Lenovo (XClarity/IMM/Spectrum)
XClarity tem Hardware > Storage em sua interface, onde são exibidos status dos RAID e das controladoras. Degraded ou Rebuild in Progress são estados que sinalizam perda de redundância e Failed indica array inoperante. É importante revisar o event log para avaliar o histórico de erros e prováveis causas.
IMM possui a seção System Status > Storage, a qual exibe a saúde de discos e volumes. Dispositivos com Warning ou Faulted (S.M.A.R.T.) são destacados. É muito útil para monitoramento remoto em data centers.
IBM Spectrum Control possui os painéis Alerts e Storage Systems, onde estão centralizadas as principais notificações de status. Alertas de Degraded, performance fora de thresholds ou Error em dispositivos IBM são gerados automaticamente.
NetApp (Unified/System Manager)
NetApp Unified Manager é uma plataforma que contém o painel Health/Storage Systems onde é possível verificar status de aggregates, volumes e disks. Degraded e Reconstructing indicam perda de redundância em RAID-DP/RAID-TEC. Failed sinaliza falha crítica.
System Manager (interface web do cluster), por meio de Storage > Aggregates, exibe status detalhados de RAID Groups. RAID reconstruction mostra progresso; warning indica predictive failure em disco; broken confirma falha definitiva.
Os comandos storage disk show -broken e aggr status -r podem ser executados através de CLI. Eles apresentam estados partial ou reconstructing, os quais revelam informações importantes.
Supermicro (IPMI / Redfish)
BMC por IPMI possui a interface Storage que exibe status de controladoras RAID (LSI/Avago). Estados Degraded ou Critical em volumes sinalizam perda de redundância; Failed confirma disco inoperante.
Redfish API (/redfish/v1/Systems/1/Storage) possui endpoints como Volumes e Drives que retornam JSON com health states Warning para predictive failures e Critical para falhas imediatas.
Procedimentos Seguros
Os procedimentos pós incidente, em um RAID, são normalmente decididos após a identificação de suas causas. Para uma dregradação que pode ser revertida de forma trivial, o processo costuma ser realizado pela equipe de storage. Para os casos de perda de acesso em um ambiente com sistema de disaster recovery atualizado, é o time de backup que geralmente entra em ação. Já quando o cenário é de perda de arquivos e com backup insuficiente, cabe aos gestores e/ou decisores avaliarem a criticidade dos dados e contratarem uma empresa especializada em recuperar dados de RAID.
Degraded / Partial Degraded
O estado Degraded informa redução na resiliência do arranjo. É comum essa anomalia ser corrigida usando os discos de spare (sobressalentes) do enclosure ou inserindo nele discos saudáveis compatíveis [em modelo e part number] com aqueles que já fazem parte da matriz degradada.
O estado Partial Degraded é uma condição peculiar a RAID-6 e RAID-60. Indica que há um disco danificado ou offline; se houver falhas adicionais no mesmo grupo, a condição agrava para Degraded ou até para Failed.
A maioria dos sistemas (controladoras de storage, servidores, appliances etc.) são previamente configurados com Auto-Rebuild em suas camadas primárias de armazenamento. Significa que o RAID será automaticamente reparado se um dos seus drives ficar offline e houver outro drive no enclosure para subsitituí-lo.
Rebuild / Sync / Resilver
Rebuilding é o processo de reconstrução de um RAID em estado Degraded ou Partial Degraded, através da redistribuição de metadados e paridade entre os discos, visando a recuperação da recundância total do array. Somente arrays com algum tipo de redundância (RAID-5, RAID-6, etc.) podem ser reparados e existem requisitos para que tal processo ocorra. O termo Syncing é usado em sistemas MD e Resilvering é usado em ZFS.
Quando o array possui um disco previamente configurado como Hot Spare, o sistema assumirá a carga e iniciará a reconstrução dos dados, de modo autônomo, assim que a falha for detectada, sem necessidade de intervenção humana. Caso não haja um spare alocado, a ação mais indicada é seguir com um hot-swap. Na maioria dos hardwares (Dell PERC, HPE Smart Array e controladoras LSI), basta remover o drive defeituoso e inserir um disco novo no mesmo slot. Se ele for compatível e estiver "limpo" (sem metadados de RAID), a controladora o reconhecerá e engatilhará o estado de rebuilding automaticamente.
Uma vez que a reconstrução do RAID degradado foi iniciada, a principal tarefa é monitorar o progresso até 100%, através dos painéis de gerência. Se o processo não for automaticamente acionado, por spare disk ou hot-swap, é possível que a função de auto-rebuild esteja desabilitada.
Failed / Unavail / Faulted
Os estados Failed, Unavail e Faulted, indicam que o RAID ficou permanentemente inoperante e inacessível. São condições em que a tolerância a falhas é excedida e não há possbilidade rebuilding.
Disaster Recovery / Backup
Nessas condições, o array entra em colapso definitivo e torna-se impossível o acesso aos seus dados. Em infraestruturas maduras, a resposta primária para o estado Failed é o acionamento do Plano de Recuperação de Desastres (DRP) ou a restauração a partir de backup validado - sendo o Bacula Enterprise a solução corporativa multiplataforma recomendada pela Hosco para orquestrar essas contingências.
O pré-requisito técnico para qualquer restauração é a substituição do hardware avariado e a criação de um novo RAID (Virtual Disk, Logical Drive, etc.). O novo arranjo deve ser inicializado nas controladoras ou por software, antes de receber o fluxo de dados. Recuperar arquivos sobre discos que participaram da falha original é um risco severo à integridade do novo ambiente.
Procedimentos por Ecossistema
Multiplataforma (Bacula Enterprise): Após inicializar o novo RAID limpo, o servidor deve ser iniciado com a ISO de resgate (BMR). O plugin do Bacula particiona o novo arranjo, restaura o sistema operacional e injeta os dados do Storage Daemon diretamente nos volumes zerados, com mínima intervenção.
Dell (PowerProtect Data Manager): Para arranjos gerenciados por controladoras PERC, os discos defeituosos devem ser substituídos e um novo Virtual Disk precisa ser criado através do iDRAC ou BIOS. O servidor deverá ser iniciado utilizando a mídia de Bare Metal Recovery do PowerProtect. No assistente, mapeiam-se os volumes de origem para o novo VD e a restauração é executada, seguida de um reboot automático.
HPE (Zerto / GreenLake for DR): Em infraestruturas ProLiant com Smart Array, a resposta inicial a uma perda de Logical Drive é acionar o Failover na interface do Zerto, direcionando o tráfego imediatamente para réplicas em um site secundário (DRaaS). Deve ser provisionado um novo Logical Drive localmente e, posteriormente, executado um Failback para retornar os dados à matriz original.
Lenovo/IBM (Storage Protect): Em ambientes com controladoras ThinkSystem ou MegaRAID, após a troca física dos drives e a criação do novo volume lógico no XClarity, o boot do servidor é realizado, por rede, apontando para o servidor do IBM Storage Protect. Por meio da interface do cliente de recuperação (BMR), os parâmetros do volume de destino são configurados e os dados são injetados diretamente no novo arranjo.
Cluster/SAN (Open-E/PetaSAN): Nestas arquiteturas de alta disponibilidade (HA) ou scale-out, a perda catastrófica de um RAID local em um Node (OSD) é suportada pela redundância de rede. Mecanismos como Stretched Clusters ou Asynchronous Replication mantêm os serviços ativos nos nós sobreviventes, enquanto o RAID do servidor afetado é reconstruído fisicamente e reintroduzido no cluster.
ZFS/OpenZFS (TrueNAS/OMV/Solaris): A recuperação exige a criação de um novo pool com discos saudáveis usando o comando zpool create. Em seguida, os datasets e zvols são restaurados, a partir do backup ou snapshot, usando uma concatenação de comandos zfs send e zfs receive, ou através de Replication Tasks nativas dos appliances.
NetApp (ONTAP): Em caso de perda total de um aggregate, a mitigação corporativa padrão ocorre por SnapMirror. O administrador orquestra o failover para o cluster secundário (site de DR). Após a troca dos discos e recriação do RAID Group no site primário, realiza-se o failback para ressincronizar a produção.
⚠️ Aviso de Sobrescrição: A criação de um novo RAID e o processo de restore destroem os dados anteriores nos drives originais. Se o backup estiver corrompido, desatualizado ou incompleto e os discos avariados forem reutilizados, a recuperação dos arquivos da matriz original será inviável.
Cenários Críticos sem Backup
Quando a indisponibilidade do RAID ocorre sem que haja um backup atualizado ou contingência de DR, o ambiente atinge seu nível máximo de criticidade. Este cenário manifesta-se tanto por múltiplas falhas físicas de drives quanto por desastres lógicos estruturais, como a exclusão acidental de um Virtual Disk / Logical Drive na controladora, a remoção de um array MD, um zpool destroy no ZFS ou a perda de metadados.
Preservação vs. Clonagens/Cópias
A diretriz inegociável para mitigar a perda de dados é a preservação imediata do ambiente. Qualquer operação de leitura ou escrita (I/O) nos discos agravará o quadro. É expressamente contraindicado tentar realizar cópias ou clonagens, fora de um laboratório controlado, em drives offline ou com suspeita de falha.
Infelizmente, pseudo-especialistas e até empresas que se intitulam "profissionais" recomendam essas práticas invasivas. Submeter um disco instável a um escaneamento de superfície ou clonagem gera estresse mecânico extremo, amplificando defeitos e acionando erros latentes de forma irreversível.
⚠️ Aviso de Inconsistência Lógica: Dispositivos (HDs, SSDs, etc.) com avarias físicas geram clones corrompidos. A tentativa de rebuild ou importação do array utilizando discos nessas condições, leva a corrupção permanente e irrecuperável da estrutura do RAID e de seus dados.
Boas Práticas vs. Ofertas Enganosas
O mercado corporativo exige cautela com "laboratórios" que se propõem a recuperar RAID apenas clonando os discos danificados e devolvendo-os para que o próprio cliente tente reinseri-los no array Failed. Esta é uma prática amadora e de alto risco.
Recuperações em RAID exigem da empresa prestadora uma estrutura para validação de arrays com formatos variados, bem como suporte a sistemas de armazenamento de famílias e fabricantes diversos. A prestadora deve ter condições de receber todos os discos do storage, reparar o RAID e devolver dados recuperados, validados e íntegros, ao cliente.
O Mito do "Diagnóstico Gratuito"
O gestor de TI deve desconfiar de empresas que alegam não cobrar por análise e diagnóstico em sistemas RAID. Os procedimentos realizados neste tipo de cenário exigem alocação intensiva de especialistas seniores e infraestrutura de ponta. Tratando-se de um trabalho de alta complexidade técnica e custo elevado, diagnósticos "gratuitos" quase sempre indicam análises superficiais, automatizadas e, frequentemente, destrutivas.
Considerações
A gestão adequada de incidentes em RAID exige cautela e aderência estrita aos protocolos de infraestrutura de TI corporativa. Como abordado, a análise minuciosa de logs e a compreensão precisa dos estados operacionais evitam que ações precipitadas agravem o cenário.
É imperativo, contudo, reconhecer o limite técnico entre a administração de sistemas e a necessidade de intervenção especializada. Procedimentos empíricos (como tentativas sucessivas de rebuild, comandos de force online ou a substituição aleatória de drives em cenários de múltiplas falhas) representam as principais causas de perda permanente de dados em ambientes corporativos.
Para cenários críticos onde o acesso aos dados foi perdido, a Hosco atua com serviços especializados na recuperação de dados em RAID, utilizando ambiente controlado, data center próprio (com IBM, Oracle/Sun, Dell e HPE), engenharia reversa para importação de RAID em ambiente isolado e tecnologias proprietárias (softwares autorais RAID Recovery e ZFS Recovery) para garantir maior eficiência e segurança no processo.